VMware vSphere GPU虚拟化Bitfusion 安装参考指南
0 总结和闭坑
- GPU作为一种加速器芯片,在机器学习特别是深度学习中得到广泛的应用
- VMware通过vSphere虚拟化平台上利用
Bitfusion解决方案使用GPU(直通模式)将GPU将物理GPU资源虚拟化进行调度并共享给多个用户 - 通过
VMDirectPath I/O技术可以让虚拟机使用GPU(直通模式) - 实际上VMware研究团队做过
虚机化平台和裸金属平台使用GPU机器学习性能这方面的测试,基本上没有性能差异;由于vSphere的优化功能,在某些测试场景中虚拟化环境下的性能甚至要比裸机环境还要好一些 - VMware的
Bitfusion解决方案类似C/S架构,Bitfusion Server端是虚拟机,通过直通模式实现物理GPU资源虚拟化,Bitfusion Client 是运行在其他 vSphere 服务器上承载着ML工作负载的 Linux 虚机,通过插件的方式把它们对于GPU的服务请求通过网络传输给Bitfusion Server,计算完成后再返回结果。对于ML工作负载来说,远程GPU是完全透明的,它就像是在使用本地的GPU硬件 Bitfusion Server·采用Photon OS 操作系统- 上述架构决定了网络的性能将对GPU的实际算力有着很大影响【这里RDMA特点凸显,InfiniBand (IB)太贵我没有条件使用】
- 整体部署难度在于自定义OVF模版中的相关参数,笔者在此环节上走过不少弯路
- 要在vSphere Bitfusion 中运行AI和ML工作流,必须在vSphere Bitfusion客户端的安装CUDA、cuDNN,一步都不能少
- 如果 vSphere Bitfusion 客户端在虚拟机 (VM) 上运行,则
必须启用所有 VMware Tools 脚本
1 前提条件
1.1 vSphere Bitfusion 服务器的系统要求
vSphere Bitfusion 需要一个 ESXi 主机,以用于安装vSphere Bitfusion服务器
当然需要更多 GPU 资源时,可以向vSphere Bitfusion集群中添加更多服务器
1.1.1 vSphere Bitfusion 服务器的系统要求
vSphere Bitfusion 服务器必须在符合以下系统要求的 vSphere 部署上运行:
- vSphere Bitfusion 4.5.0 或 4.5.1 服务器设备的最低磁盘空间要求为 50 GB
- vSphere Bitfusion 4.5.2 服务器设备的最低磁盘空间要求为 75 GB
- 运行 vSphere Bitfusion 服务器的 ESXi 主机版本必须为 7.0 或更高版本
- vSphere Bitfusion 服务器的最低内存要求为 32 GB 或服务器上安装的 GPU 内存总量的 150%(取较高者)
- vSphere Bitfusion 服务器的最低虚拟 CPU (vCPU) 要求是 GPU 卡数乘以 4
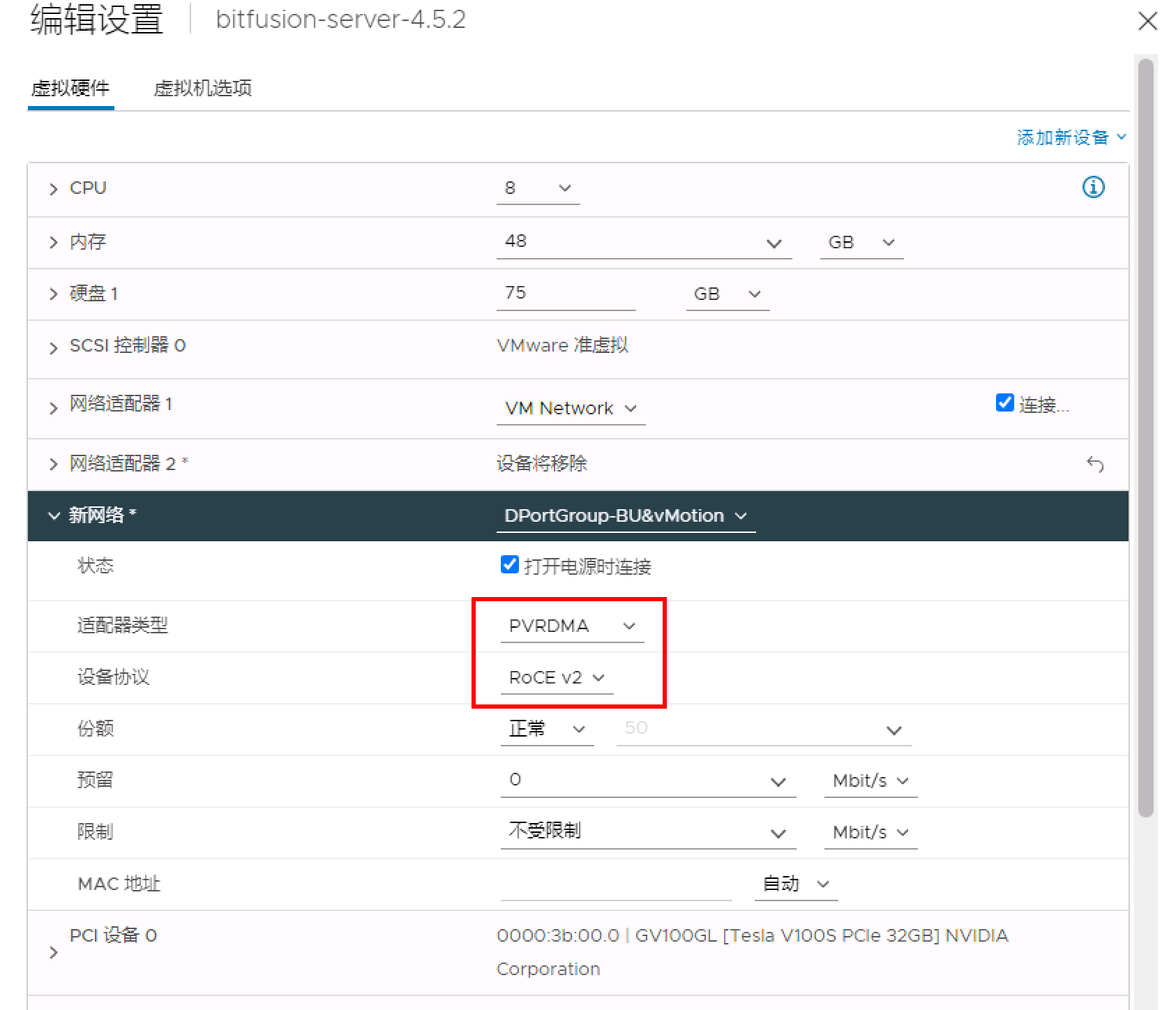
- 网络支持 TCP/IP 和/或 RoCE(PVRDMA 适配器)。【RoCE为协议】
- vSphere Bitfusion 服务器上每两个 GPU 至少配置 10 Gbps 的带宽
- 客户端计算机与服务器虚拟机之间的延迟不得超过 50 微秒。这并非严格要求,但延迟越低,vSphere Bitfusion 部署的性能越好
- 所有 vSphere Bitfusion 服务器都必须连接到同一组有效的 NTP 服务器
1.2 vSphere Bitfusion 客户端的系统要求
vSphere Bitfusion 需要在虚拟机、裸机计算机或容器上安装 vSphere Bitfusion 客户端
1.2.1 vSphere Bitfusion 客户端的系统要求
- vSphere Bitfusion 客户端的最低磁盘空间要求为 2 GB。
- vSphere Bitfusion 客户端的最低内存要求是至少为应用程序请求使用的 GPU 内存的 150%。
- vSphere Bitfusion 客户端的最低虚拟 CPU (vCPU) 要求与使用本地专用 GPU 运行应用程序的要求相同。
- vSphere Bitfusion
客户端目前版本必须安装在使用以下操作系统之一的计算机上
- CentOS 7
- Red Hat Linux 7.9
- Red Hat Linux 8.5
- Ubuntu Linux 18.04
- Ubuntu Linux 20.04
- Ubuntu Linux 22.04
- SUSE Linux 15.3
1.2.2 虚拟机的必备条件
如果 vSphere Bitfusion 客户端在虚拟机 (VM) 上运行,则必须启用所有 VMware Tools 脚本。在创建新的虚拟机时,将在默认配置中启用脚本
1.2.3 虚拟机的其他必备条件
如果 vSphere Bitfusion 客户端在与 vSphere Bitfusion 服务器属于同一 vCenter Server 实例的虚拟机上运行,则其他系统要求也适用
- vSphere Bitfusion 客户端虚拟机必须在由 vCenter Server 7.0 管理的 vSphere 部署上运行
- vSphere Bitfusion 客户端必须安装在 ESXi 主机 6.7 或更高版本上
1.3 bitfusion架构
参考官网图片

2 部署准备
2.1 部署流程图
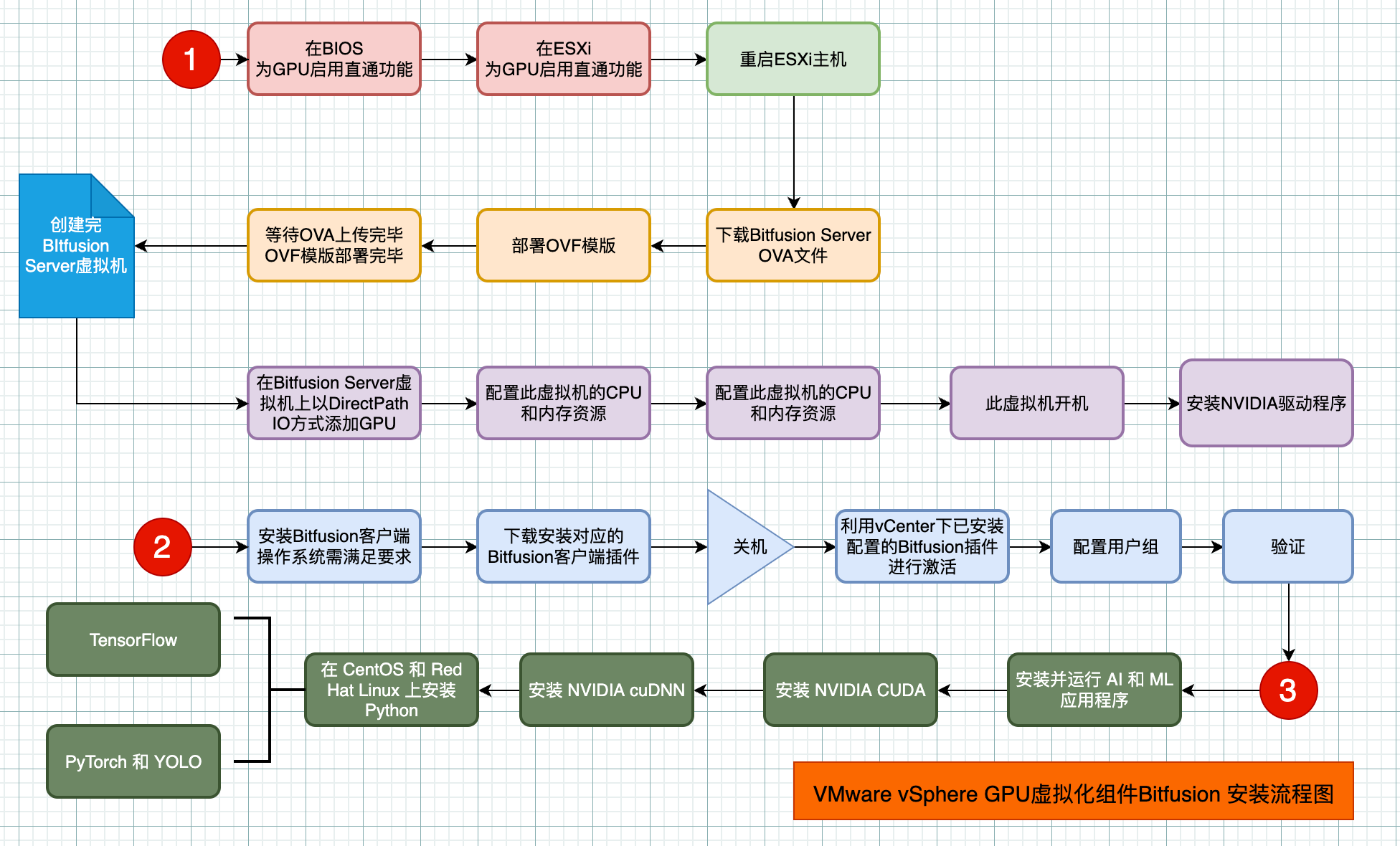
2.3 为GPU启用直通功能
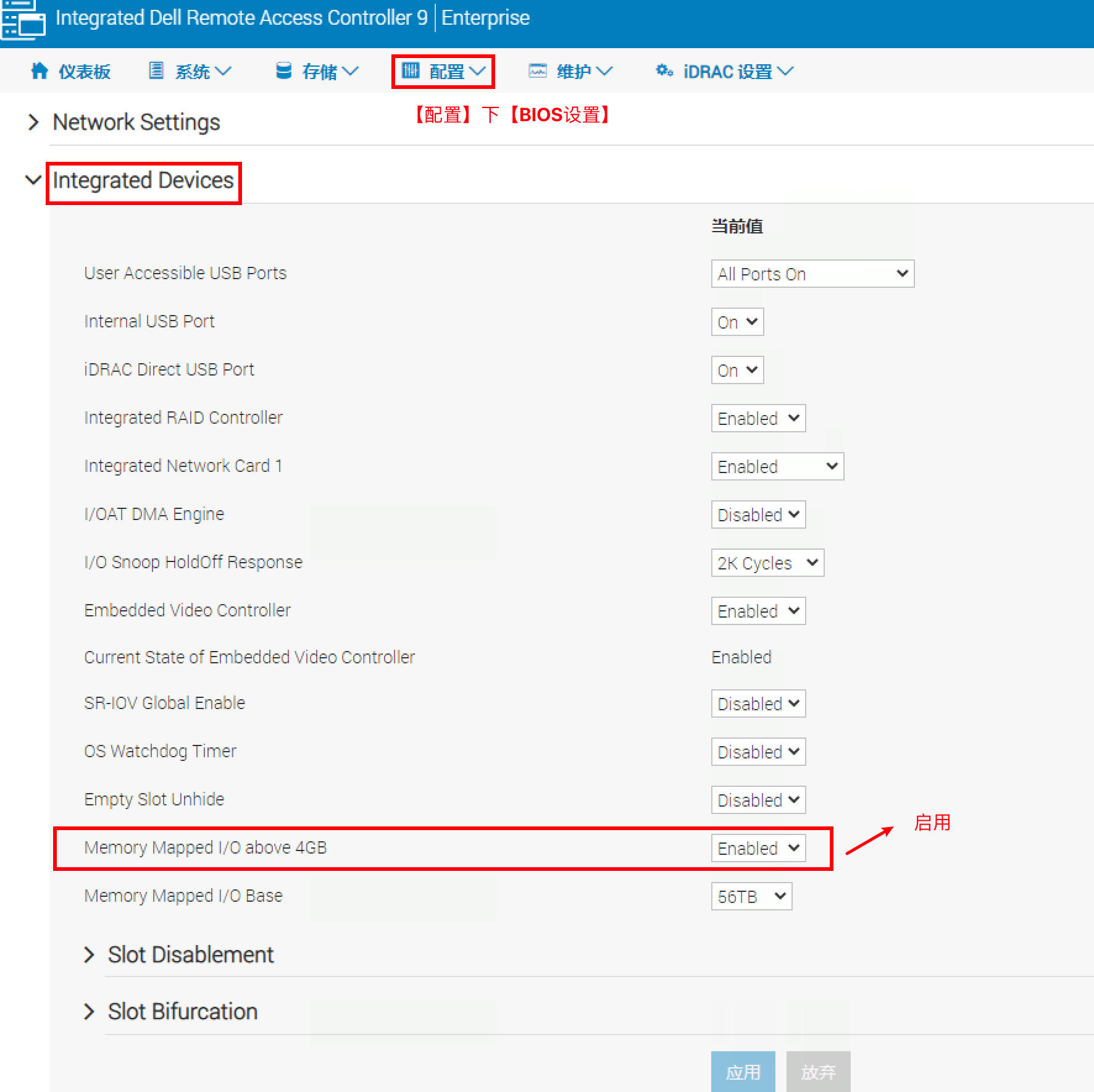
ESXi 主机的 BIOS 设置中为 GPU 启用直通
通常情况下,设置的名称为 Above 4G decoding、Memory mapped I/O above 4GB 或 PCI 64-bit resource handing above 4G
在 ESXi 主机上为 GPU 启用直通
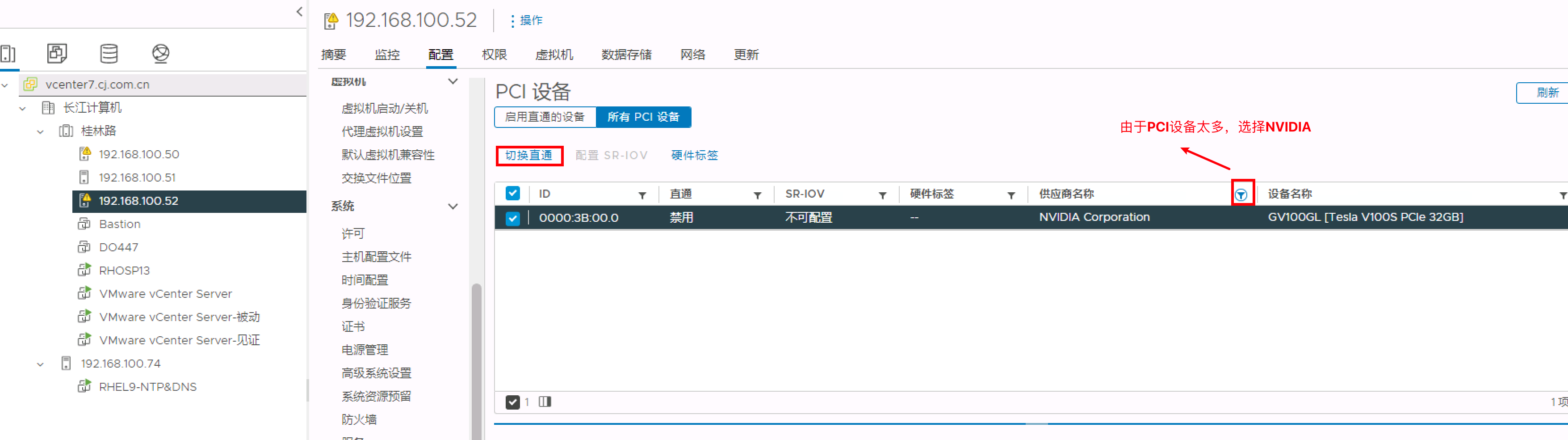
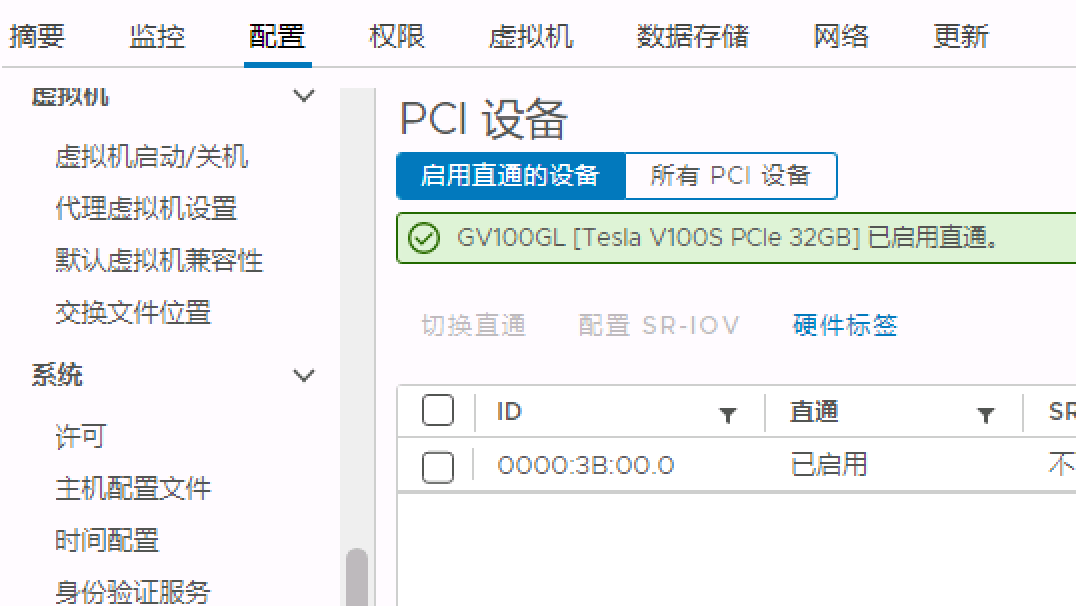
GPU 将在启用直通的设备选项卡上显示
配置完成后,务必重新引导 ESXi 主机
2.2 安装
2.3.1 下载ova文件
从https://my.VMware.com/downloads/下载 vSphere Bitfusion OVA 文件
2.3.2 部署OVF模版
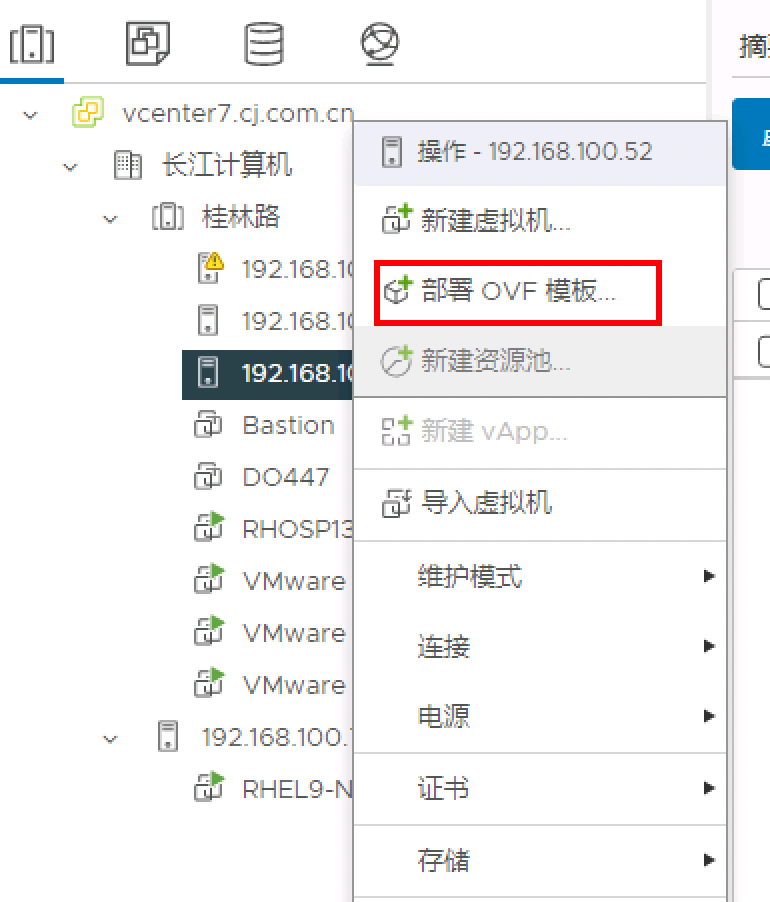 OVF
OVF
选择本地OVA文件【本次案例为2022-06-23发布的4.5.2】
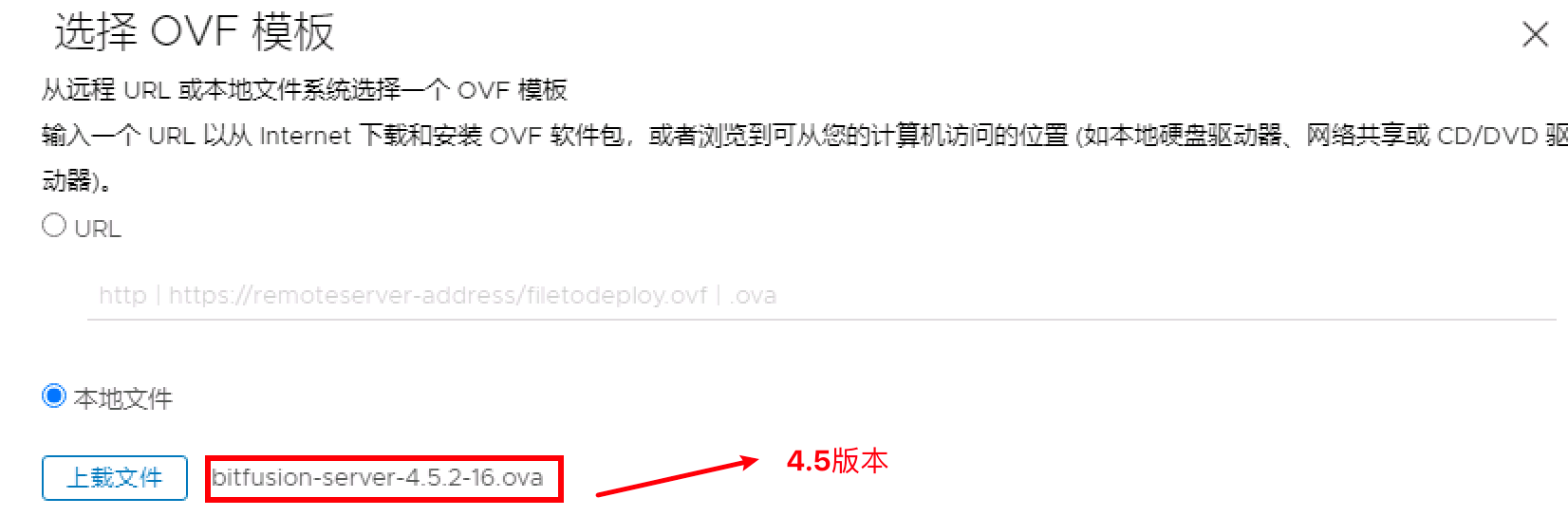
选择主机
查看详细信息
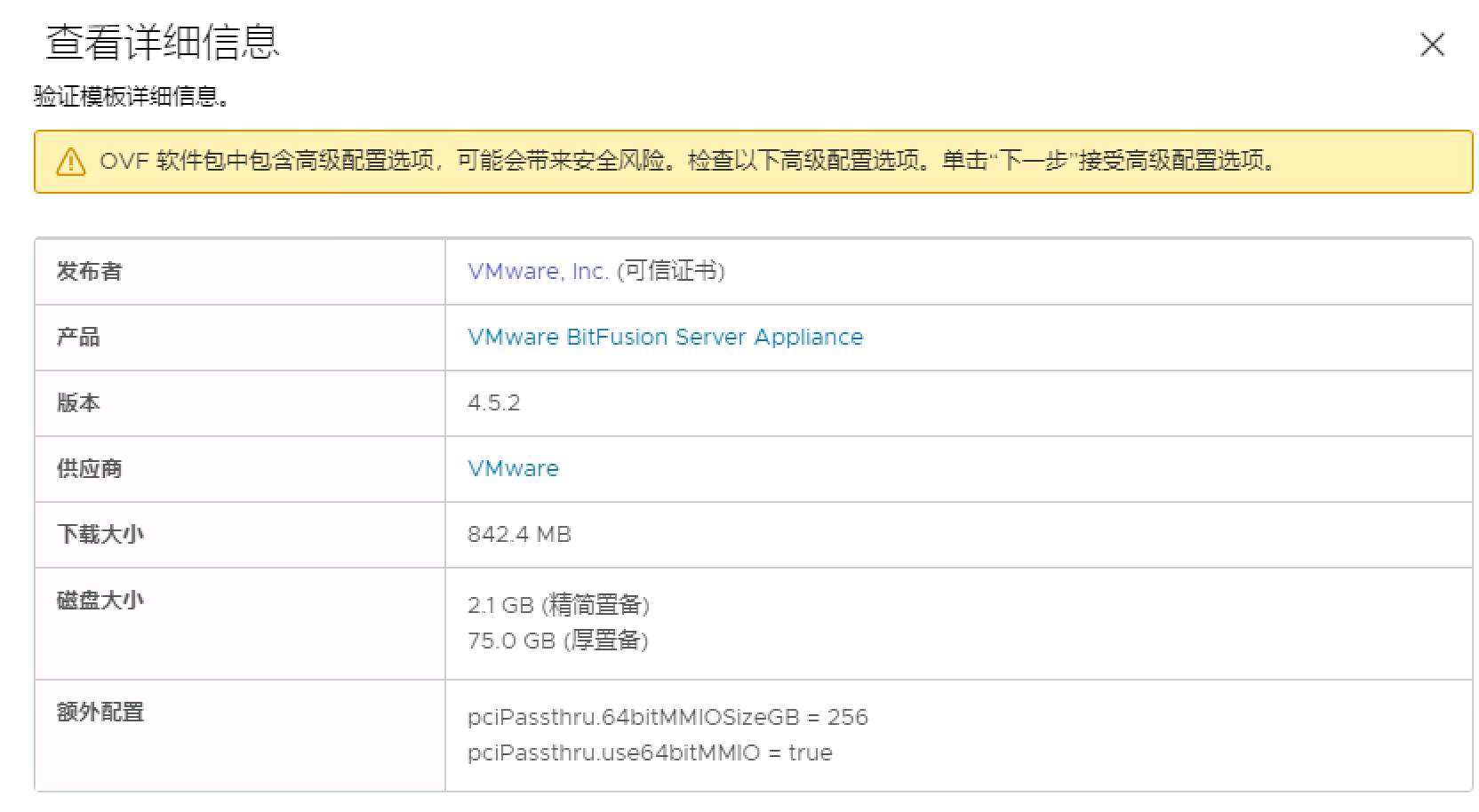
查看详细信息页面将显示一条警告,指明 vSphere Bitfusion OVF 使用高级配置值,可能会带来安全风险
触发警示的配置值是 pciPassthru.use64bitMMIO = true 和 pciPassthru.64bitMMIOSizeGB = 256
第一个参数将为 GPU 设备启用 PCI 直通,GPU 设备需要具有 16 GB 或更多的内存映射
第二个参数将配置内存映射 I/O (MMIO) 大小 256 GB。您可以稍后在 vSphere Bitfusion 虚拟机的设置中调整此值
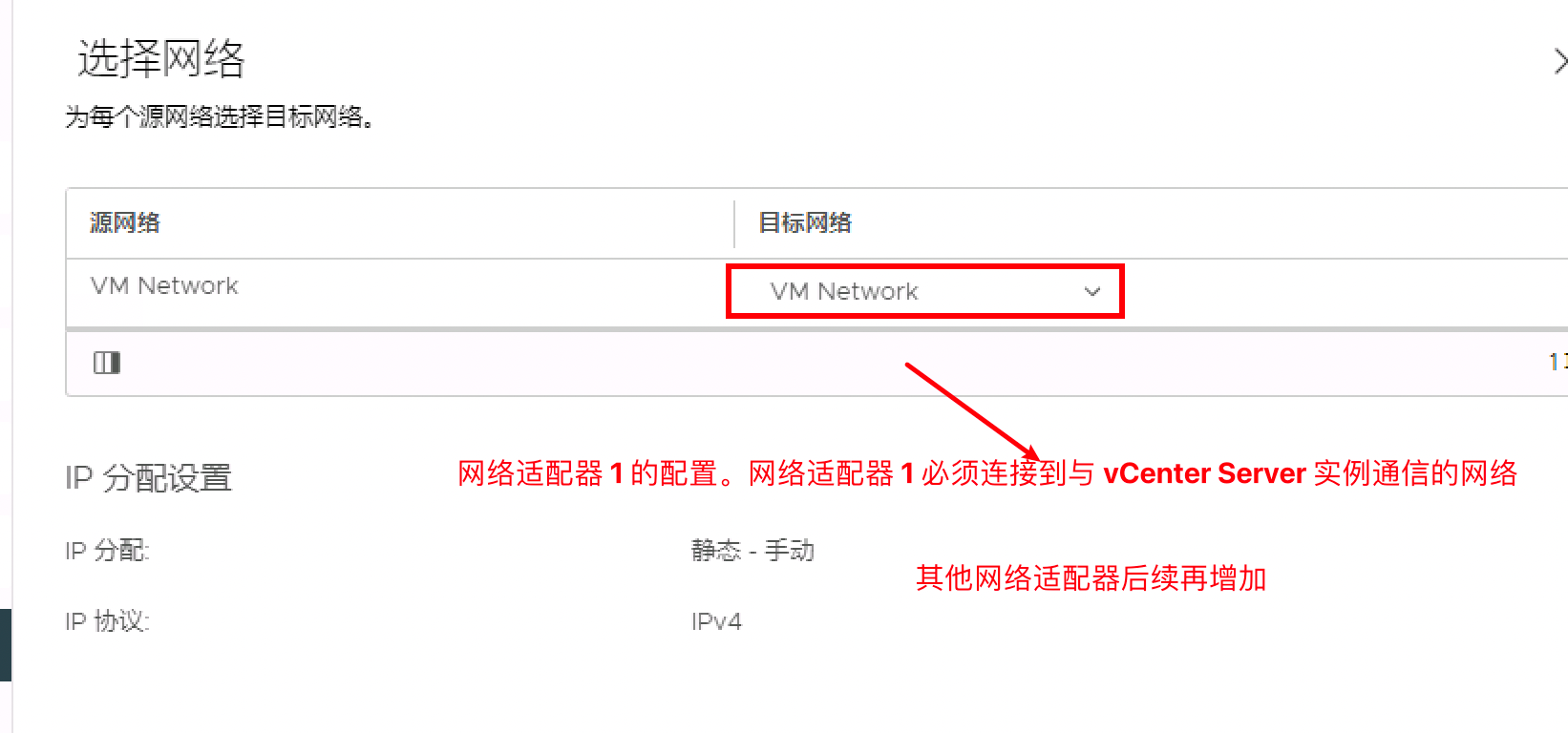
选择网络
2.3.3 自定义OVF模版
- 设置hostname名称
- 在 Bitfusion 服务器设置部分中,输入要在其上部署 vSphere Bitfusion OVF 模板的 vCenter Server 实例的用户名和密码。
- 在 Bitfusion 服务器设置部分中,输入 vCenter Server TLS 证书指纹【实际上不需要填写】
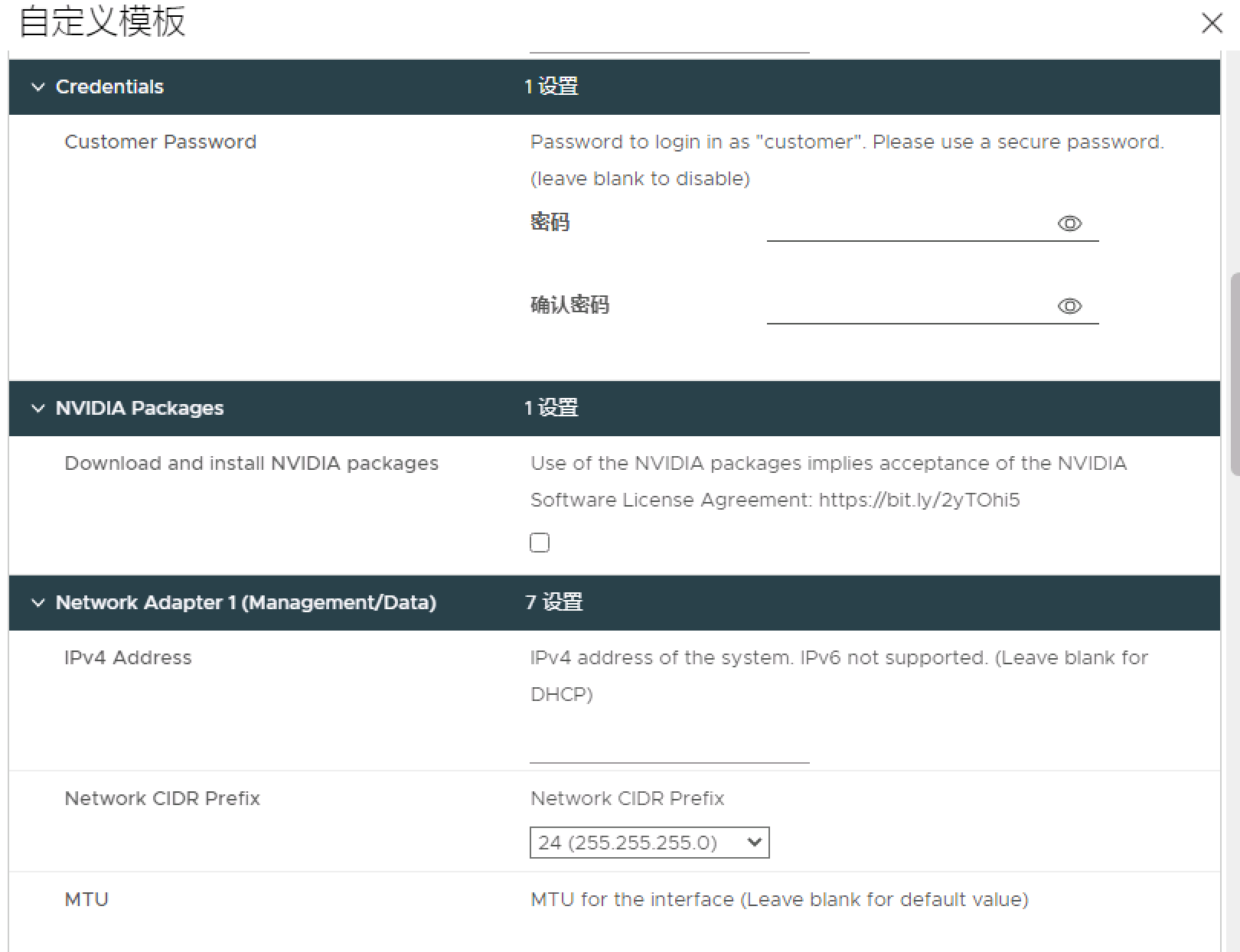
1、在凭据部分指定客户密码【虽然可选,但是建议进行选择,务必注意,用户名是customer】
建议配置凭据,因为如果需要手工安装NVIDIA驱动程序,需要使用该账户登录后使用提权方式进行安装
部署完成后,使用客户用户帐户通过控制台 shell 或 SSH 登录到 vCenter Server Appliance。
2、在 NVIDIA 软件包部分中,选中下载并安装 NVIDIA 软件包复选框以接受 NVIDIA 许可证。
通过接受 NVIDIA 许可证, vSphere Bitfusion 会在首次引导虚拟机期间下载并安装 NVIDIA 驱动程序、CUDA 库和 NVIDIA Fabric Manager
如果在无法访问 Internet 的环境(例如,使用气隙网络)中运行 vSphere Bitfusion,请不要选中该复选框
必须在部署 vSphere Bitfusion 设备后手动下载并安装 NVIDIA 软件
注意
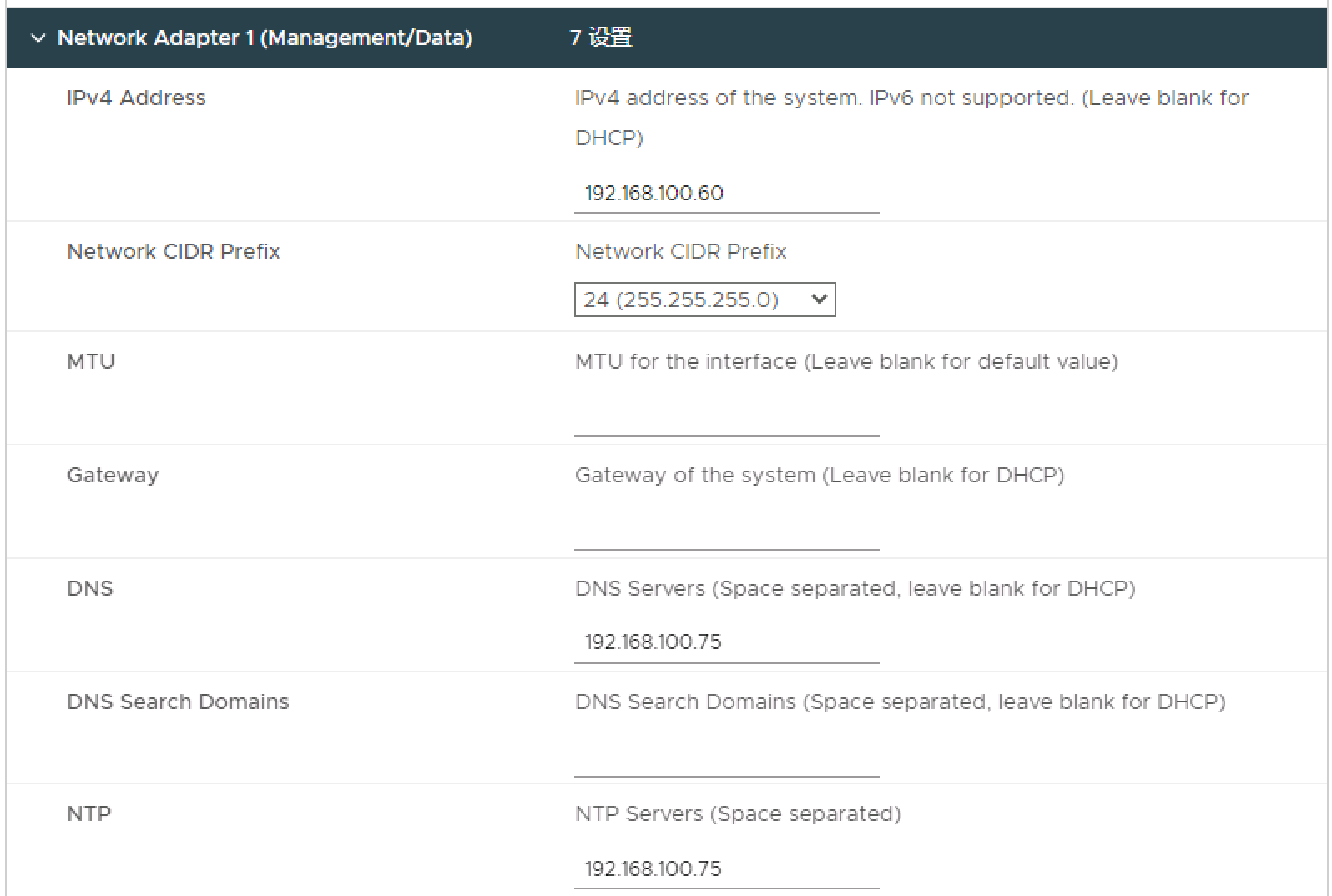
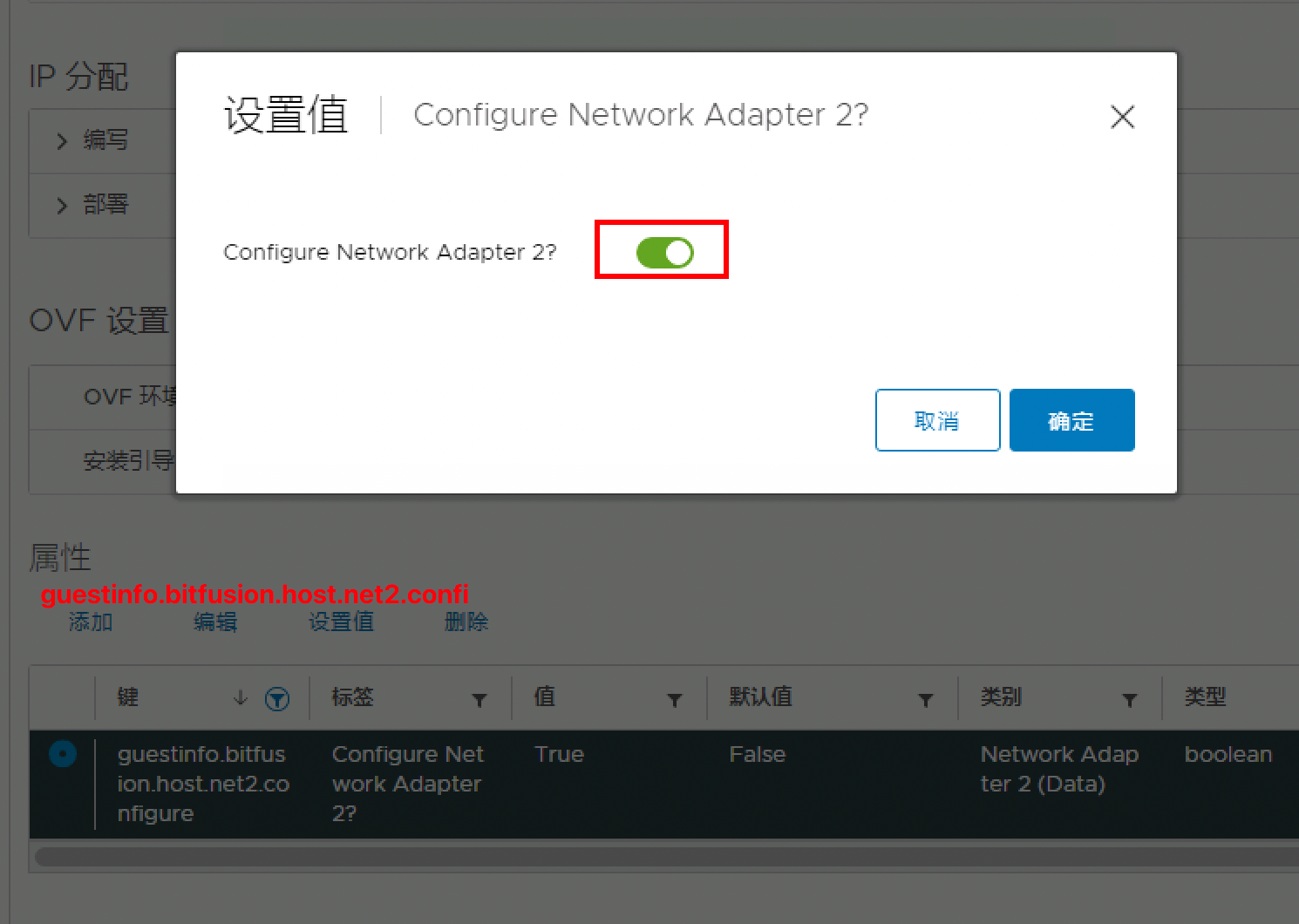
必须指定用于管理和数据流量的网络适配器 1 的配置。网络适配器 1 必须连接到与 vCenter Server 实例通信的网络
网络适配器 2、3 和 4 是可选的,并且仅用于数据流量。每个网络适配器都必须连接到单独的网络
vSphere Bitfusion 会选择可将数据最高效地传输到 vSphere Bitfusion 服务器的网络。
3 配置Bitfusion服务器
3.1 添加 GPU 设备
- 在 vSphere Client 中,右键单击清单中的 vSphere Bitfusion 虚拟机,然后选择编辑设置。
- 在虚拟硬件选项卡上,单击添加新设备按钮。
- 从下拉菜单中的其他设备下,选择 PCI 设备。
- 展开 新 PCI 设备部分,然后选择访问类型。
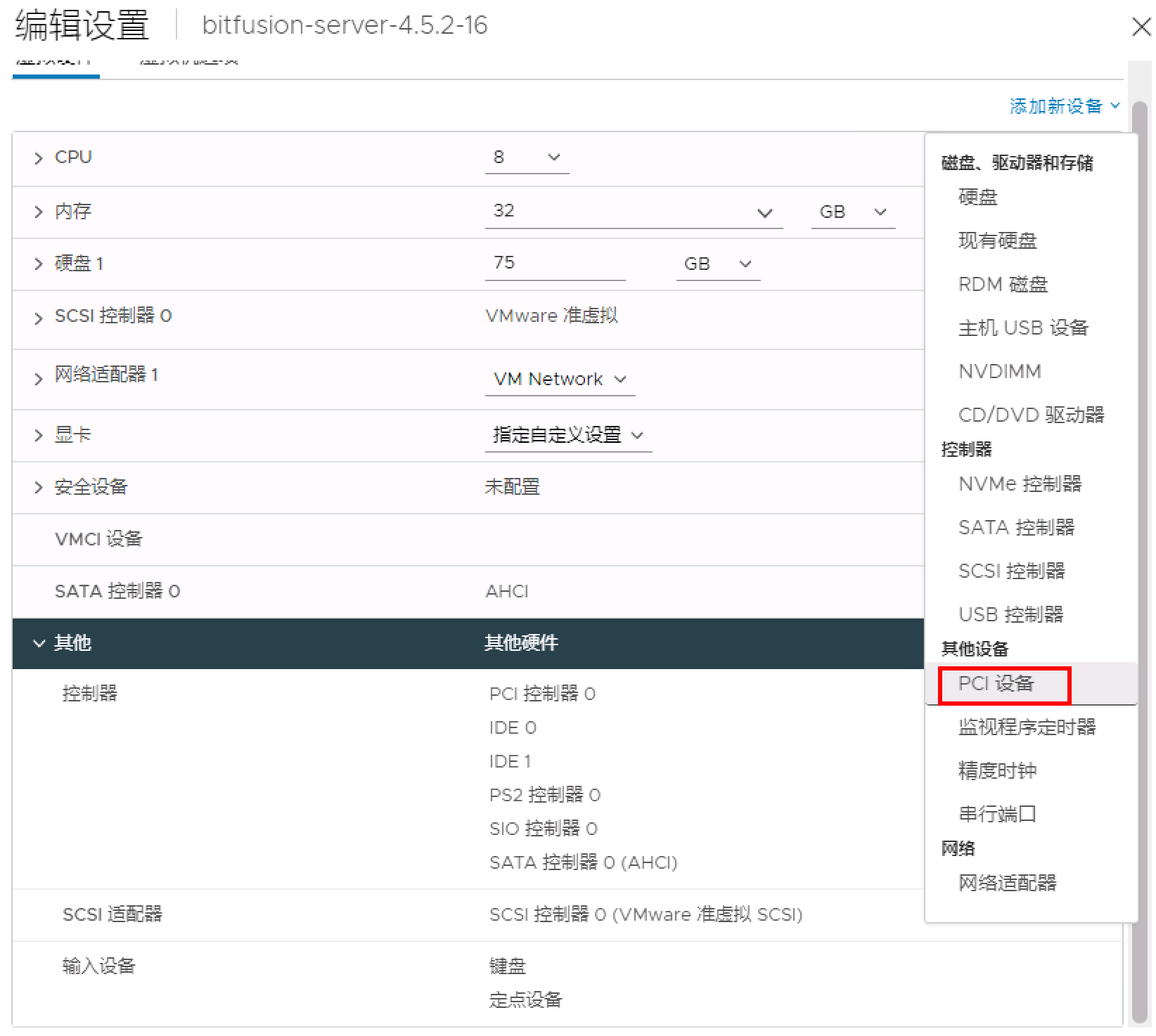
选择添加本次GPU卡,Tesla V1000 32GB
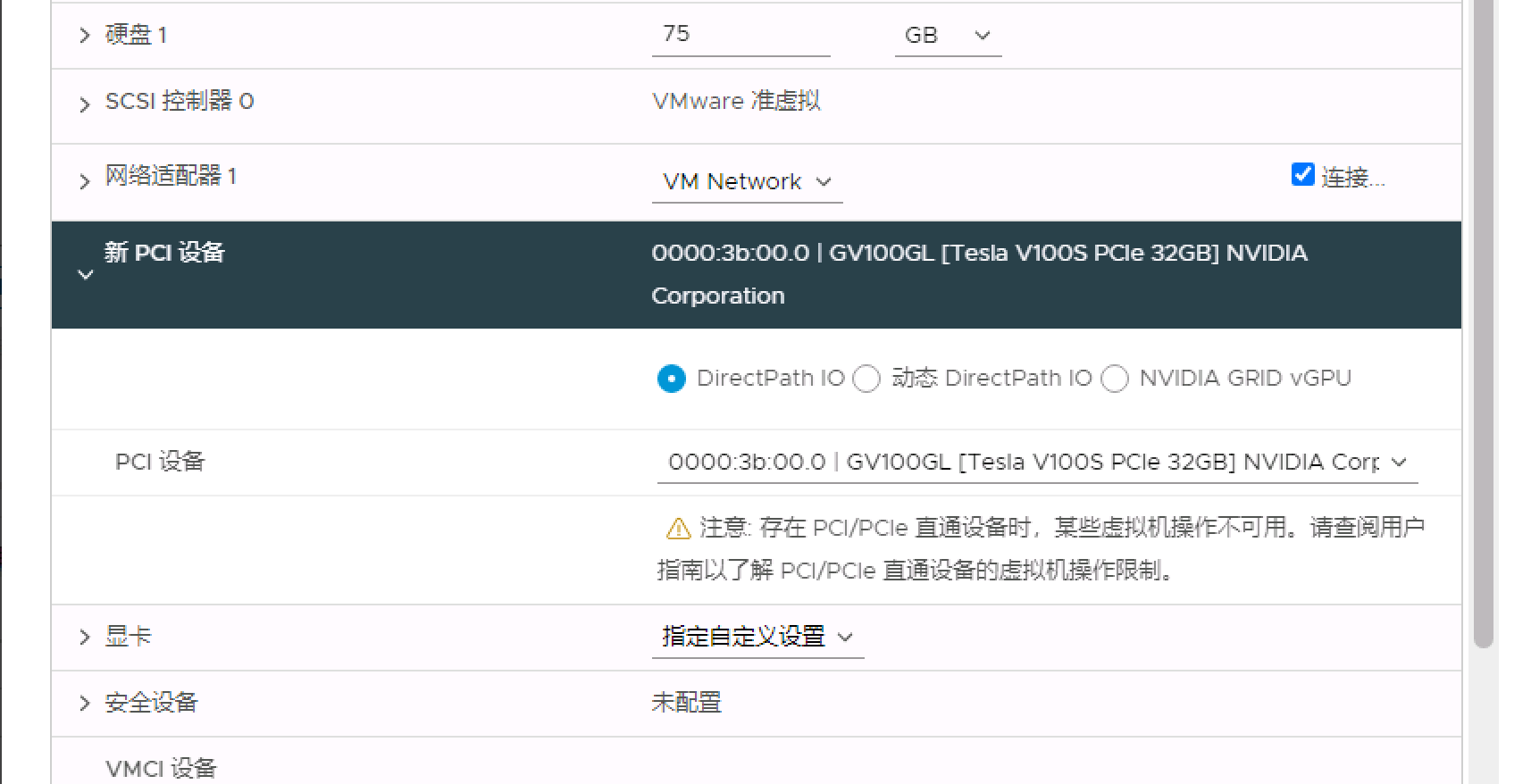
关于VMDirectPath I/O
VMDirectPath I/O 允许客户机操作系统直接访问 GPU,从而绕过 ESXi Hypervisor
通过使用直通设备,可以更高效地使用资源,并提高 vSphere Bitfusion 环境的性能,启用 GPU 直通可在 vSphere 上提供接近于其本机系统的性能级别
3.2 为 ESXi 主机配置 CPU 和内存资源
如果 ESXi 主机专用于 vSphere Bitfusion 服务器,请将 CPU 和内存设置为其最大值
如果主机不是专用于 vSphere Bitfusion
请将最小 CPU 值指定为 GPU 数量乘以 4
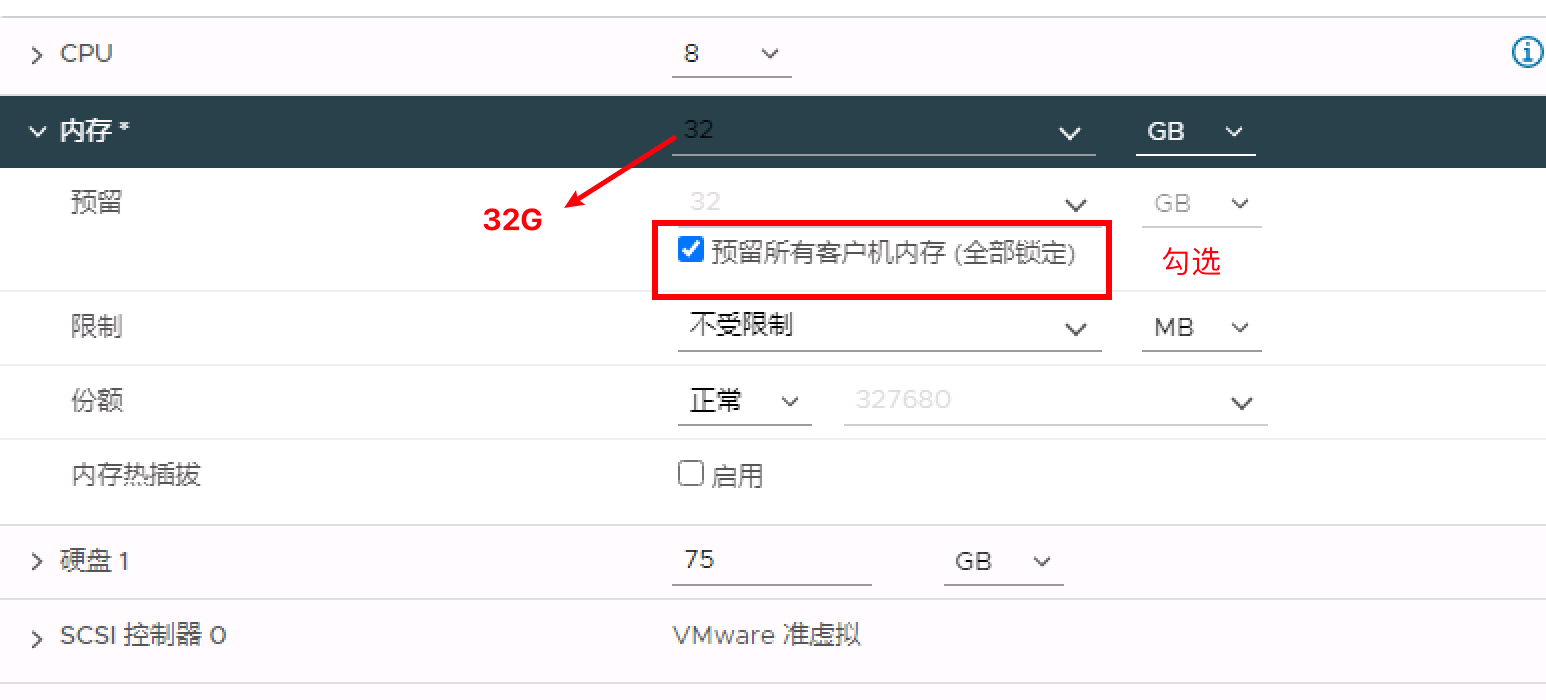
将最小内存值指定为汇总 GPU 卡内存的 1.5 倍或 32 GB(取较大者)
在 vSphere Client 中,右键单击 vSphere Bitfusion 虚拟机,然后选择编辑设置。
- 展开 CPU 部分,然后编辑资源
- 展开内存部分,然后编辑资源
- 在内存下,选中预留所有客户机内存 (全部锁定) 复选框
3.3 打开bitfusion server虚拟机电源
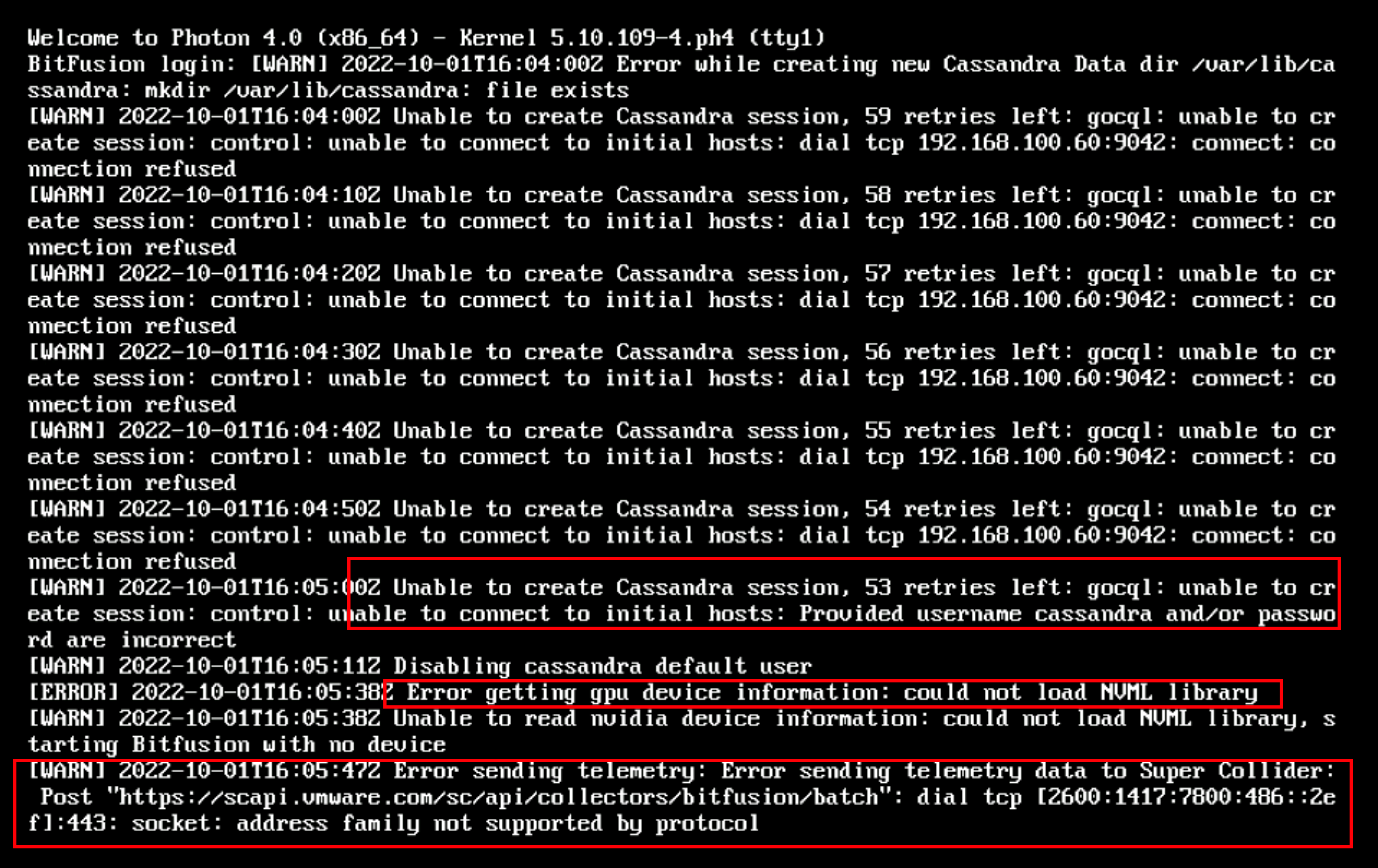
打开虚拟机电源,耐心等待
关于cassandra报错属于正常
由于我们在定义OVF模版中并没有安装nividia驱动,会报could not load NVML library错误,属于正常
安装完成后,浏览器会提示已成功部署插件

实际上会再vSphere安装部署Bitfusion插件,这点很重要
从日志查看安装日志

4 继续配置vSphere Bitfusion 服务器
4.1 添加新网络
可将 vSphere Bitfusion 服务器的虚拟机连接到最多四个网络。
在 vSphere Bitfusion 服务器的部署过程中,必须至少配置用于管理和数据流量的网络适配器 1。网络适配器 2、3 和 4 是可选的,并且仅用于数据流量。要在服务器部署完成后添加用于数据流量的网络接口,请执行以下过程。
每个网络适配器都必须连接到单独的网络。 vSphere Bitfusion 会选择可将数据最高效地传输到 vSphere Bitfusion 服务器的网络。
展开新网络部分,然后从适配器类型下拉菜单中选择要分配给虚拟机的网络适配器。
vSphere Bitfusion 支持 VMXNET3 和 PVRDMA 适配器。
4 添加后续的 vSphere Bitfusion 服务器
如果需要更多GPU资源时,可以向 vSphere Bitfusion 集群中添加更多服务器
可以使用 vSphere Bitfusion 插件将后续 vSphere Bitfusion 服务器添加到集群
该插件使用主服务器的配置数据,可以更快地部署后续服务器。
添加的 vSphere Bitfusion 服务器必须与第一个 vSphere Bitfusion 服务器一起由同一个 vCenter Server 实例进行管理
5 安装NVIDIA驱动程序
在Bitfusion Server虚拟机上安装NVIDIA驱动程序
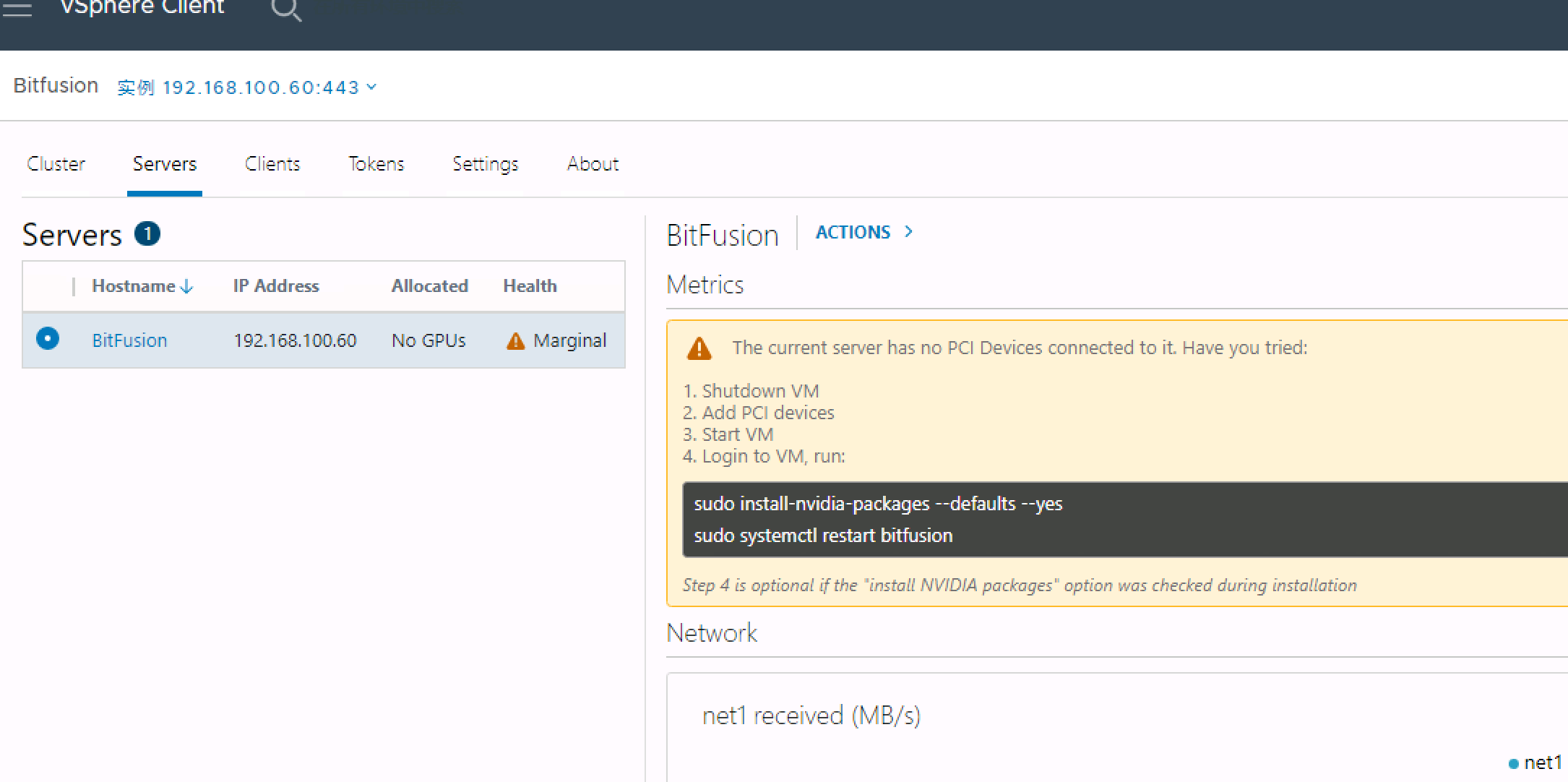
选择NVIDIA驱动
注意
经认证可与 vSphere Bitfusion 4.5.0 和 4.5.1 配合使用的 NVIDIA 驱动程序为
NVIDIA-Linux-x86_64-460.73.01.run经认证可与 vSphere Bitfusion 4.5.2 配合使用的 NVIDIA 驱动程序为
NVIDIA-Linux-x86_64-470.129.06.run
可以采用离线或者在线安装方式
1、在线安装
但是需要使用在自定义OVF模版中设置的customer账户和密码,利用提权方式在线安装
1 | sudo install-nvidia-packages --defaults --yes |
2、离线安装
前提是在本地某台机器上临时部署一个http web server,将驱动程序拷贝至http可访问位置
1 | sudo install-nvidia-packages --driver http://172.18.2.12/NVIDIA/NVIDIA-Linux-x86_64-470.129.06.run |
安装完驱动程序后,VMware vCenter将显示Bitfusion集群及GPU相关信息
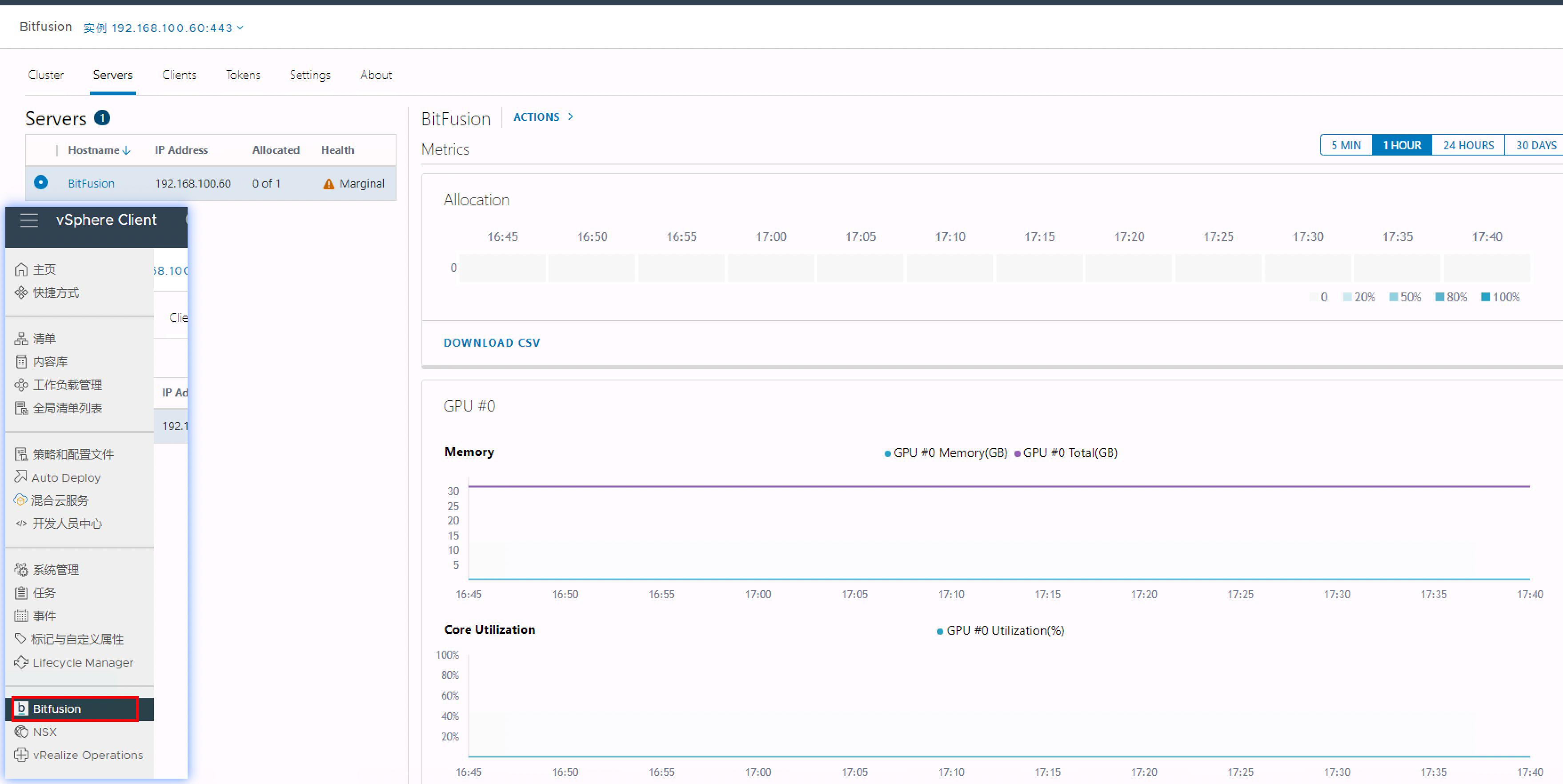
6 安装 vSphere Bitfusion 客户端
从 VMware 网站https://packages.VMware.com/bitfusion/ubuntu/ 下载适用于您的Linux发行版的vSphere Bitfusion 客户端插件
1、ubuntu 2204
1 | wget https://packages.VMware.com/bitfusion/ubuntu/22.04/bitfusion-client-ubuntu2204_4.5.2-16_amd64.deb |
2、RHEL 7/8
本实验基于RHEL8.6版本测试
1 | wget https://packages.VMware.com/bitfusion/rhel/8/bitfusion-client-rhel8-4.5.2-16.x86_64.rpm |
安装Bitfusion客户端插件后,关闭虚拟机
7 利用插件激活客户端
针对上述完成Bitfusion客户端插件后的虚拟机,在VM电源关闭状态下利用vCenter下已安装配置的Bitfusion插件进行激活
7.1 前提条件
请再次检查环境
确认您已安装适用于 Linux 操作系统的 vSphere Bitfusion 客户端
确认 vSphere Bitfusion 客户端与 vSphere Bitfusion 服务器位于同一 vCenter Server 实例
确认 vSphere Bitfusion 客户端的版本不高于 vSphere Bitfusion 服务器的版本
确认 vSphere Bitfusion 客户端的虚拟机 (VM) 已关闭电源
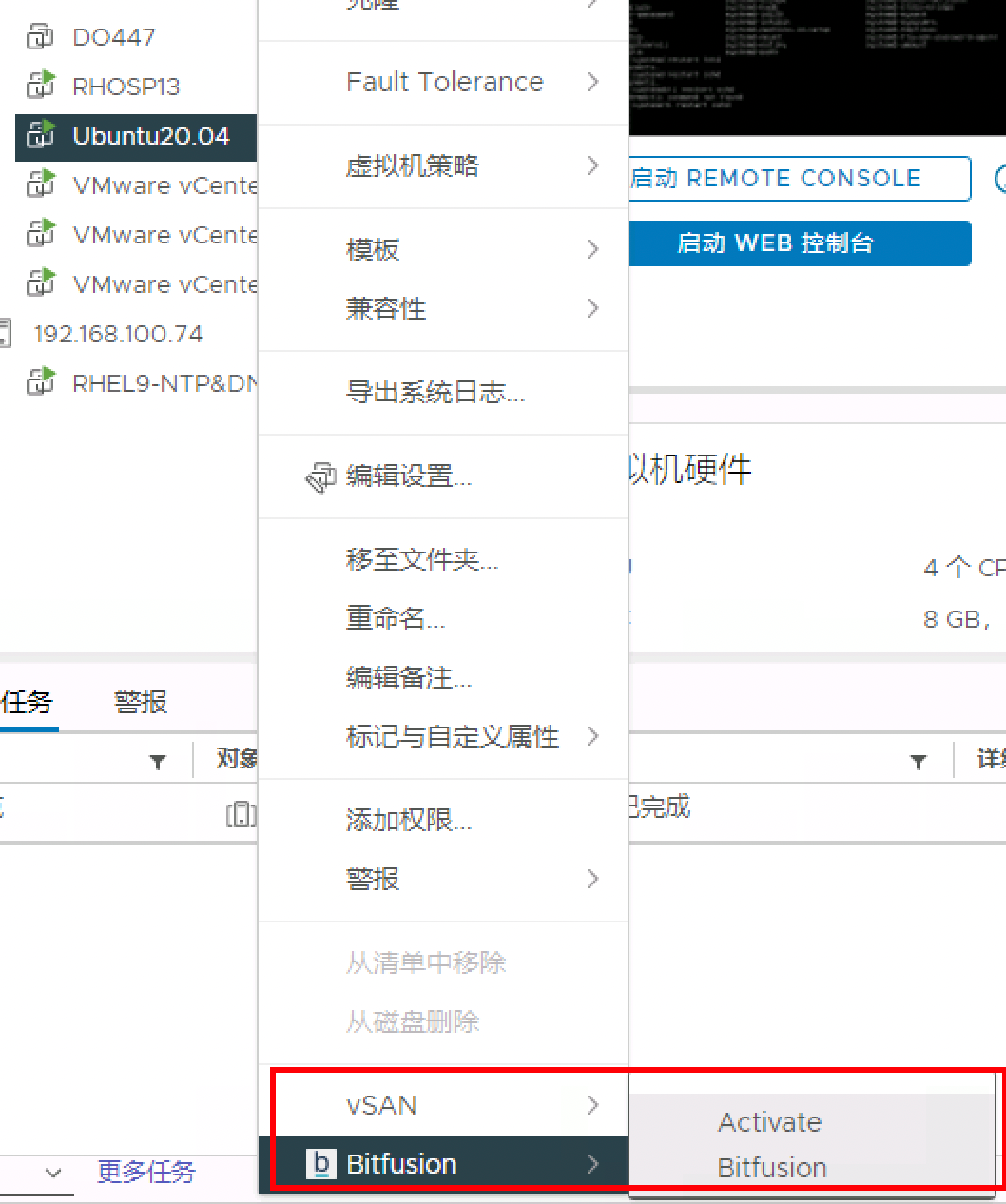
选择第一项,作为客户端
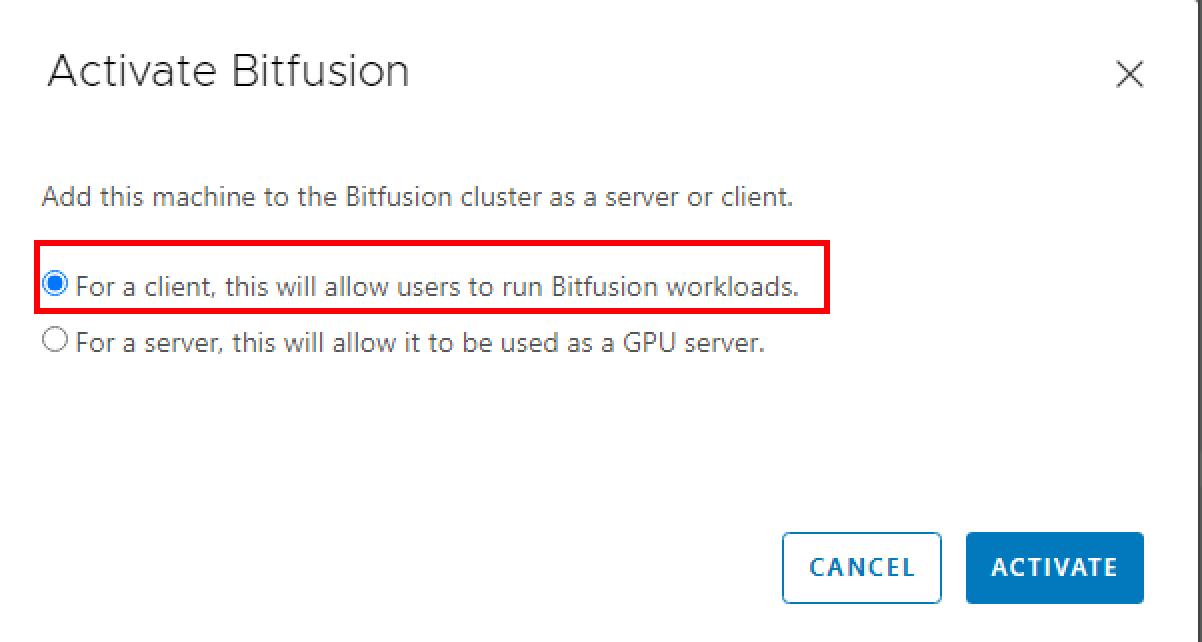
7.2 配置用户组
打开客户端虚拟机电源
在客户端计算机的终端中,通过运行 sudo usermod -aG bitfusion username 命令将用户添加到 vSphere Bitfusion Linux 用户组,其中 username 是新用户的名称
1 | usermod -aG bitfusion root |
7.3 验证
1 | $bitfusion list_gpus |
至此,Bitfusion服务端和客户端的安装基本完毕
8 部署使用实例
要将 AI 和 ML 应用程序与 vSphere Bitfusion 配合使用,请安装并配置多个软件包和编程框架
8.1 安装 NVIDIA CUDA
统一计算设备架构 (CUDA) 是由 NVIDIA 开发的一种并行计算平台和编程模型,用于在图形处理单元 (GPU) 上进行常规计算
CUDA 可利用 GPU 的处理能力大幅提高计算应用程序的速度。例如,TensorFlow 和 PyTorch 基准测试使用 CUDA
要下载适用于 CentOS 8 或 Red Hat Linux 8 的 NVIDIA CUDA 11 软件包
rpm包比较大,安装起来倒是很快
1 | $wget https://developer.download.nvidia.com/compute/cuda/11.0.3/local_installers/cuda-repo-rhel8-11-0-local-11.0.3_450.51.06-1.x86_64.rpm |
安装cuda包比较多,达214个
1 | $yum -y install cuda |
8.2 安装 NVIDIA cuDNN
NVIDIA CUDA Deep Neural Network (cuDNN) 是一个 GPU 加速的原语库,用于深度神经网络
8.2.1 前提条件
- 创建一个 NVIDIA 开发人员帐户,以从该帐户下载与您的 NVIDIA CUDA 版本匹配并适用于您的 Linux 发行版的 cuDNN 软件包。请参见
https://developer.nvidia.com/cudnn - 确认您已安装 vSphere Bitfusion 客户端。
- 确认您已安装 NVIDIA CUDA。
1 | $wget https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/libcudnn8-8.0.5.39-1.cuda11.0.x86_64.rpm |
【本人是直接通过https://rhel.pkgs.org/网站上直接下载】
1 | https://developer.download.nvidia.com/compute/cuda/repos/rhel8/x86_64/libcudnn8-8.0.5.39-1.cuda11.0.x86_64.rpm |
安装
1 | $rpm -ivh libcudnn8-8.0.5.39-1.cuda11.0.x86_64.rpm |
验证
1 | $ldconfig -p | grep cudnn |
验证python3 版本
1 | $dnf install python3 |
8.3 安装 pip3
1 | sudo yum install -y python36-devel |
使用 pip3 install 命令安装 TensorFlow。
1 | sudo pip3 install tensorflow-gpu==2.4 |
8.4 安装 TensorFlow 基准测试
TensorFlow 基准测试是用于测试 TensorFlow 框架性能的开源 ML 应用程序。
如果使用的是 CentOS 或 Red Hat Linux,则必须安装 Python 3
您可以针对 TensorFlow 基准测试创建分支并下载到本地环境中。
前提条件:确认您已安装 TensorFlow。
1 | yum install git |
导航到存储库的基准目录和列表分支
1 | git branch -a |
切换到cnn_tf_v2.1_compatible分支
1 | git checkout cnn_tf_v2.1_compatible |
确认当前路径
1 | $pwd |
要使用 tf_cnn_benchmarks.py 基准测试脚本,请运行 bitfusion run 命令
通过运行示例中的命令,可以使用单个 GPU 的全部内存和 /data 目录中预安装的 ML 数据
1 | bitfusion run -n 1 -- python3 \ |
要使用 tf_cnn_benchmarks.py 基准测试脚本,请使用 bitfusion run 参数运行 -p 0.67 命令。
通过运行示例中的命令,将使用单个 GPU 中 67% 的内存和 /data 目录中的预安装 ML 数据。使用 -p 0.67 参数,您可以在 GPU 剩余的 33% 内存分区中运行另一个作业。
1 | Running warm up |
可以通过具有共享 GPU 的 vSphere Bitfusion 从远程服务器运行 TensorFlow 基准测试,可以在vCenter的Bitfusion插件中查看GPU负载情况
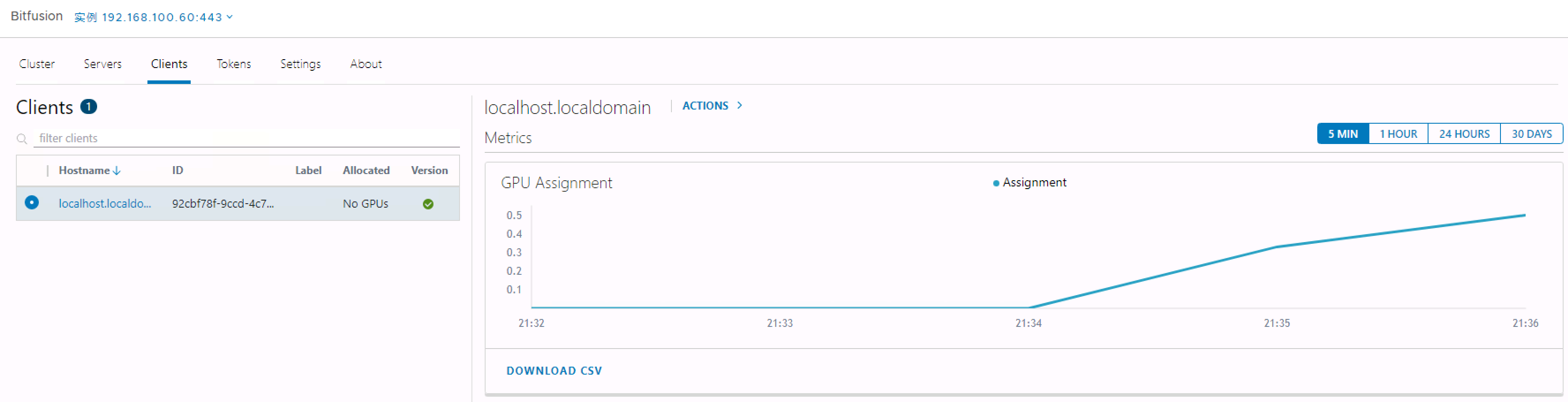
9 优化建议:将 vSphere Bitfusion 与 PVRDMA 结合使用
可以将准虚拟远程直接内存访问 (PVRDMA) 适配器与 vSphere Bitfusion 服务器和客户端结合使用,以提高集群的性能
在 vSphere Bitfusion 中运行 ML 和 AI 工作负载的优势之一是保持 GPU 工作管道处于占满状态,从而隐藏网络延迟
由于GPU管道无法始终保持占满状态,因此建议使用延迟为50微秒或更短的低延迟网络连接
远程直接内存访问 (RDMA) 允许从一台计算机的内存直接内存访问另一台计算机的内存,而不会涉及操作系统或 CPU
内存的传输卸载至支持 RDMA 的主机通道适配器 (Host Channel Adapter, HCA)通常在 RDMA 网络中使用大型最大传输单元 (MTU),例如每帧 9000 字节,直接访问和大型帧大小相结合,不仅降低了网络开销和延迟,而且提高了 vSphere Bitfusion 的性能
虚拟远程直接内存访问 (PVRDMA) 支持通过分布式网络在虚拟机 (VM) 之间实现 RDMA,而无需使用 DirectPath I/O 将整个物理适配器专用于虚拟机
PVRDMA 网络适配器可在虚拟环境中提供远程直接内存访问,其中虚拟机可以位于同一物理主机上,也可以位于同一网络中的其他主机上
如果未使用 DirectPath I/O,并且支持 RDMA 的物理适配器和交换机可用,则建议使用 PVRDMA,而不使用 VMXNET3