M-LAG(下·排障篇):排障不是碰运气,是沿着流量走一遍
排障最怕的一句话,是”重启一下试试”。
好了就烧香,没好就升级工单——这不叫排障,叫碰运气。碰运气最大的代价还不是慢,而是即便”好了”,你也不知道它为什么坏、为什么好。没找到根因的恢复,只是故障在憋一个更大的招。
网络排障之所以可以不靠运气,是因为转发是一个确定性系统:任何一个包,在任何一跳的去向,都由那一跳的表项写死——服务器查自己的路由表和 ARP 缓存,bond 查成员状态和 hash 结果,交换机查 MAC 表、ARP 表、路由表,防火墙查会话表和安全策略。没有一跳是掷骰子。
所以排障的唯一正道,就是标题这句话:沿着流量走一遍。知道这个包正常时每一跳怎么走、每一跳查哪张表,故障时就逐跳把表翻出来对——表和预期第一次对不上的那一跳,就是故障点。
这是 M-LAG 三部曲的终章。上篇把心智模型焊进了脑子——对外一台、对内两台;同步靠 peer-link,裁决靠 DAD;中篇按依赖顺序把这台”演出来的设备”搭了起来。这篇讲第三个时态:穿帮了,怎么救。
本篇三步走:
- 先把各类流量逐包推演一遍——正常怎么转、故障怎么绕。这是排障的地图;
- 再按部件拆解四大故障场景的排查路径——每一步敲什么命令、该看到什么、看到什么说明什么。这是拿着地图找断点;
- 最后附七个生产环境经典坑——每一个都是真实运维里反复出现的翻车现场。
命令与回显基于真机环境:华为 CloudEngine CE6856-48T6Q-HI,版本 V200R023C00SPC500,拓扑与地址规划完全沿用中篇(部署篇)。
一、逐包推演:先知道包正常怎么走
1.1 M-LAG 排障的两条心法
进入逐跳推演之前,先给两条 M-LAG 特有的心法。它们能在排障的第一分钟,就把范围砍掉一大半。
心法一:”一半通、一半不通”不是玄学,是 hash。
LACP 和 ECMP 都按流做负载分担:把报文头里的一组字段(哈希因子——可能是源目 MAC、源目 IP,配置了增强模式后还包括四层端口)喂进哈希函数,同一条流的字段不变,哈希结果就不变,永远走同一条路。同一条流永远走同一条路(中篇用伪代码推演过这件事)。这意味着,M-LAG 里单台设备的路径故障,现象一定是**”确定的一半流被判了死刑,另一半安然无恙”**:
- ICMP 的 hash 输入里没有四层端口,同一对主机之间的 ping,hash 结果是恒定的——所以表现是这台机器 ping 网关永远不通、旁边那台永远通,而不是”时好时坏”;
- TCP/UDP 按端口散列,同一台主机上有的连接通、有的不通——宏观上就成了运维最讨厌的”业务时通时不通”。
散列是 hash 的规范中文译名,下文两词混用,散列是 hash 的规范中文译名(散列函数 = 哈希函数)
ping 报文的哈希输入只有源 IP + 目的 IP(ICMP 没有端口,退化为纯 L3 哈希;ICMP 头里虽然有 identifier 和 sequence 字段,但它们不是哈希因子)
TCP/UDP:哈希依然确定,但操作系统在替你”掷骰子”,因为源端口是操作系统从临时端口范围(Linux 默认 32768–60999)里为每一条新连接动态分配的
所以听到”时通时不通”,第一反应不该是”网络在抖”,而是先问一句:**”哪一半?”** 顺着不通的那条流,找到它被 hash 到的那台设备——故障就在那台设备的转发路径上。这一问,直接把排查范围从”整张网”缩小到”半张网”。
心法二:peer-link 的流量水位,是 M-LAG 的”体温计”。
下面的推演会反复验证上篇的一个结论:正常情况下,业务流量基本不碰 peer-link——它是”同步主干道 + 故障备用道”,不是流量主干道。反过来讲:
peer-link 上突然出现大量业务流量,本身就是故障信号——说明有流量在绕行,某处的成员口或上行链路已经出了问题。display interface Eth-Trunk0 看一眼流量水位,往往比翻日志更快”量出体温”。
1.2 一次完整的南北向旅程:九跳,五张表
拿最常见的流量开刀:服务器 172.18.3.10(bond 双归到 SwitchA / SwitchB)ping 一次防火墙之后的互联地址 8.8.8.8。一个 ICMP Echo Request 出门,一个 Echo Reply 回家,正好构成一次完整往返。把它一跳一跳铺开,每一跳标注两件事:谁在做决策,查的是哪张表。
第 0 跳,服务器的路由决策。 8.8.8.8 不在自己的 172.18.3.0/24 里——查本机路由表,结论:交给网关 172.18.3.254。要封装以太帧,还差网关的 MAC——查本机 ARP 缓存。缓存里有,直接跳到第 3 跳;没有,先走一趟 ARP。
第 1 跳,ARP 请求出门。 ARP 请求是广播帧,但聚合口对同一份帧只从一个成员口发送——bond 按 hash 选一条腿把它发出去。假设这次落到了 SwitchA【实际上因为输入恒定,所以这台主机的 ARP 永远走SwitchA,直到成员链路数量变化(某条腿 down 掉导致模数改变)】。
完整流程:
广播帧 → 洪泛决策(逻辑口粒度):发往 bond0,一份 → 成员选择(物理口粒度):hash(帧头字段) → 选中 eth0 → 从 eth0 发出
第 2 跳,SwitchA 应答,SwitchB 同步。 三件事同时发生(严格来说是同一个触发事件派生出三条互不等待的处理路径):
- 请求的目标 IP 是 SwitchA 自己的 VLANIF105,报文上送控制面,SwitchA 回 ARP 应答,源 MAC 是虚拟网关 MAC
0000-5e00-0011——服务器从此认定网关就长这张脸;
服务器缓存这张脸多久
Linux 不是简单的定时删除,而是邻居状态机,所以只要流量持续,这条表项实际上永不失效,只是周期性被重新确认。交换机侧的 ARP 老化时间完全是另一个量级——华为默认 20 分钟
- SwitchA 从这份 ARP 帧上学到两条表项——帧头源 MAC + 入端口写进 MAC 表(数据面),载荷里的 Sender IP/Sender MAC 写进 ARP 表(控制面)。一份帧,喂饱两张表,并经 peer-link 把表项同步给 SwitchB(DFS Group 的本职),从此流量无论 hash 到哪台,两边查到的都是同一条映射、指向各自本地的成员腿——转发决策等价,且都不必借道 peer-link;
SwitchA 上这条 MAC 指向它自己的 M-LAG 成员口(比如 Eth-Trunk 10),SwitchB 收到同步表项后,写进自己表里的出接口不是 peer-link,而是 SwitchB 本地的同编号 M-LAG 成员口。因为 M-LAG 的抽象契约就是:两台设备各自的成员腿,对外是同一个逻辑接口
- 广播帧本身照泛洪规则复制:VLAN 105 的其它本地端口一份、peer-link 一份。到了 SwitchB 的那份,照常泛洪给单归端口和上联口——唯独被单向隔离拦在双归成员口之前——服务器不会收到自己广播的回音,环也成不了。
单向隔离的规则只有一条,且极其精确
规则是:从 peer-link 收到的报文,不允许从 M-LAG 双归成员口发出
但是注意,单归端口(orphan port,只接在 SwitchB 上的设备):正常发,而且必须发
第 3 跳,ICMP 去程,hash 定命运。 服务器封装 ICMP,目的 MAC 0000-5e00-0011。这条流的 hash 输入是(172.18.3.10, 8.8.8.8, ICMP)——ICMP 没有 L4 端口,layer3+4 策略在这里退化为只看 IP 对,所以这台服务器 ping 8.8.8.8 的所有报文永远走同一条腿。假设这次落到了 SwitchB。
注意:和第 1 跳的 ARP 落到 A 毫不冲突,每条流各走各的 hash。
ARP 是非 IP 帧,退化为 layer2 公式,输入 = 源MAC XOR 目的MAC(ff:ff:ff:ff:ff:ff) XOR 类型(0x0806);ICMP 走 layer3+4 公式,无端口可用,实际输入退化为源目 IP。两者因子不同、公式不同,落点是两次相互独立的计算——可能同腿也可能异腿。但每条流自己的输入恒定,落点一经算出便不再变化。这就是 per-flow 的本义:不保证不同的流走不同的路,只保证同一条流永远走同一条路。
顺带一句:如果把 ping 换成 TCP,戏剧性会更足——源端口每次连接都变,同一台服务器访问同一个目的地,第一条连接可能 hash 到 A,第二条就到 B。”per-flow”三个字的含义,在这里体现得最彻底。
第 4 跳,SwitchB 本地路由。 帧的目的 MAC 命中 SwitchB 自己的网关 MAC——这就是双活网关”两台都是真网关”的落点:B 不需要把帧推给 A,自己拆帧进三层,查路由表:去 8.8.8.8,下一跳 10.104.1.13(防火墙),出接口 10GE1/0/33。本地进、本地转,不碰 peer-link。
第 5 跳,防火墙去程。 查安全策略、建会话表、转发。此刻会话表里记下了:这条流是从接 SwitchB 的那个接口进来的。记录入接口是状态检测防火墙的本职,首包查策略、建会话表,后续包靠会话直接放行:会话表项里除五元组、NAT 关系外,天然包含入接口,回程识别和反向 NAT 都依赖它。记住这个字段——回程时它会开口说话。
第 6 跳,回程,防火墙自己 hash。 回包目的 172.18.3.0/24,防火墙路由表里是两条 ECMP 等价路由。命中两条 ECMP 等价路由,路由系统必须二选一。选择手段以逐流哈希为绝对主流(缺省即是),逐包轮询虽存在但因乱序风险几乎无人启用,假设这次选了 10.104.1.10——SwitchA。
去程走 B、回程走 A——来回不同路。这不是异常,是双活加 ECMP 的常态。交换机是无状态设备,来回走谁都无所谓。(记住这个画面,坑七会翻旧账。)
注意:记了状态为什么还要 hash?
因为会话表和转发决策是两套系统。会话表是安全机制:回包到达时用来匹配”这是既有会话的返程”,免查策略、做反向 NAT。
注意:来回不同路的真正原因是什么?
去程和回程是两台不同设备、在两个不同时刻、用两组不同输入做的两次独立哈希,没有任何机制把它们绑在一起。去程选路的是上游交换机(它的哈希因子、算法、种子);回程选路的是防火墙自己(自己的因子和算法),而且回程报文的源目 IP 恰好颠倒。per-flow 哈希只承诺”同一设备上、同一方向的流永远走同一条路”,从未承诺”正反向走同一条路”。
第 7 跳,SwitchA 回程三层。 连查三张表:查路由表——172.18.3.0/24 是直连 VLAN 105;查 ARP 表——172.18.3.10 的 MAC 赫然在列,这就是第 2 跳那次同步的兑现:A 明明没和服务器做过这轮 ARP,表里却有;查 MAC 表——出接口 Eth-Trunk5,从本地成员口直接送下去(本地优先转发,不绕 peer-link)。
第 8 跳,服务器收包。 一次往返落幕。
把整趟旅程收进一张表——左边是包的旅程,右边是人的排障地图:
| 跳 | 决策者 | 查的是哪张表 | 排障时对表的命令 |
|---|---|---|---|
| 0 | 服务器 | 本机路由表、ARP 缓存 | ip route / ip neigh(Linux) |
| 1、3 | 服务器 bond | 成员状态 + hash 结果 | cat /proc/net/bonding/bond0 |
| 2 | SwitchA | 上送控制面;MAC/ARP 学习与同步 | display mac-address vlan 105 / display arp |
| 4 | SwitchB | MAC 表(命中网关 MAC)、路由表 | display ip routing-table |
| 5 | 防火墙 | 会话表 + 安全策略 | 防火墙侧会话与策略查询 |
| 6 | 防火墙 | 路由表(ECMP hash) | display ip routing-table 172.18.3.0 |
| 7 | SwitchA | 路由表、ARP 表、MAC 表 | 同第 4 跳 |
这张表就是”沿着流量走一遍”的全部含义:故障时,从第 0 跳开始逐行对表,第一行对不上的地方,就是断点。
再补一个值得焊进脑子的观察:整趟往返,peer-link 上跑过的只有第 2 跳的表项同步报文、和那份被单向隔离兜住的广播——没有一个业务包。心法二的依据,就在这里。
1.3 东西向与 BUM:三种简短的旅程
同网段二层(Server1 到 Server2,都双归): hash 到哪台,哪台查 MAC 表,从本地成员口直接送达,一跳都不多走。唯一合法绕 peer-link 的情况:目的设备单归挂在对端——本端没有它的本地出口,只能借道过去。
跨网段三层(VLAN 105 到 VLAN 106): hash 到哪台,哪台就是网关,本地查路由直接转。双活网关的”双活”再次兑现——不存在”备网关收到流量要先交给主网关”这回事,”备”只是裁决序位,不是转发身份。
广播 / 组播 / 未知单播(BUM): 入口那台向本 VLAN 的所有本地端口加 peer-link 泛洪一份;对端那台收到 peer-link 来的副本后,只向自己的单归口和上行口泛,不向双归的成员口泛(单向隔离)——下游双归设备永远只收到一份,不重复、不成环。
1.4 故障怎么绕:同一张地图上的四次改线
上面是”正常怎么转”,现在推演”故障怎么绕”。M-LAG 的所有故障切换,本质都是改表:哪张表被改、改成什么样,决定了流量绕哪条线。按部件过一遍——
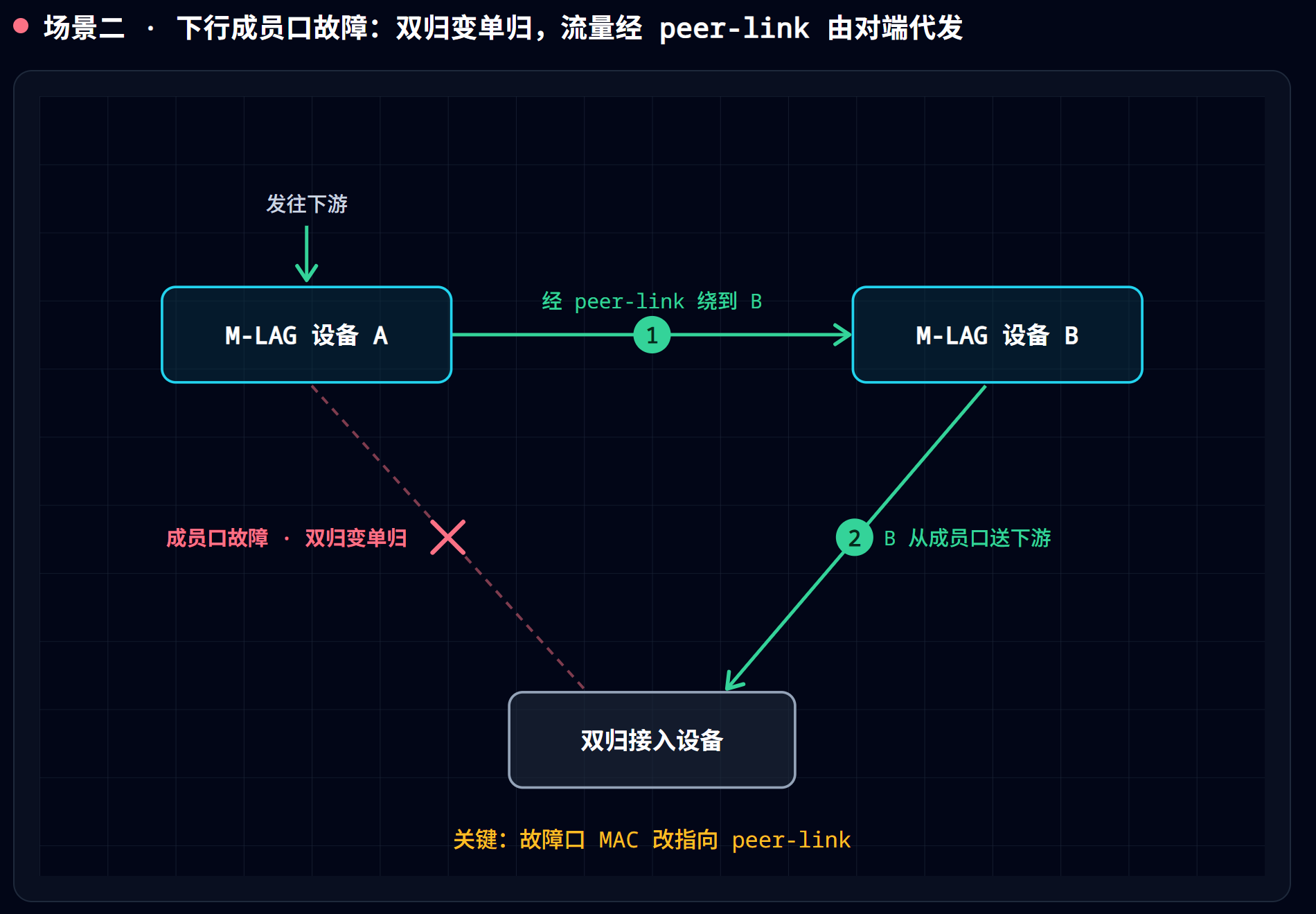
成员口断(南向): 两侧各改一张表。服务器侧,LACP 探测到那条腿 Down,bond 把流量全部压到另一条腿——服务器自己改了成员表;交换机侧,断口那台把该服务器的 MAC 表项改指 peer-link——上游若仍把回程流量交给它,它就经 peer-link 甩给对端、由对端送达。上游 Spine 和防火墙全程无感。
上行断(北向): 我们的组网北向是独立三层对接,所以这是一次纯路由表的改线:断口那台的 OSPF 邻居 Down,直连出口路由撤销,SPF 重算,逃生链路那条 cost 101 的路由上位——被 hash 过来的流量多绕一跳(本机、逃生链路、对端、防火墙),一个包不丢;防火墙侧同步收敛,ECMP 从两条归一。服务器全程无感——它的两条腿物理上都还好好的。(若是纯二层接入上游的组网,二层流量的绕行走 peer-link——peer-link 本就是二层链路,天生支持。二层与三层在这里的分野,上篇场景一讲透了。)
整机宕: 上面两种改线同时发生——南向 LACP 收敛加北向 OSPF 收敛,全量流量归另一台。这也是为什么容量规划时,单台必须能扛住全部带宽。
peer-link 断: 最特殊的一次”改线”——改的不是转发表,是成员资格:DAD 确认对端还活着之后,裁决让备机把业务口全部 error-down,从物理上退出演出。下游看到的只是”少了一条腿”,LACP 把流量全部切到主机那一侧。
一张表总结四次改线:
| 断点 | 谁先感知 | 改的是哪张表 | 流量绕行路径 | 谁全程无感 |
|---|---|---|---|---|
| 成员口 | 服务器 LACP + 本端交换机 | bond 成员表;MAC 表改指 peer-link | 回程借 peer-link 到对端 | 上游 |
| 上行口 | OSPF(邻居 Down) | 路由表:逃生路由上位 | 本机经逃生链路到对端再出 | 服务器 |
| 整机 | LACP 与 OSPF 同时 | 以上两类同时改 | 全量归另一台 | —— |
| peer-link | DFS / DAD | 不改转发表,改成员资格(error-down) | 全量归主 | 下游(只觉得少了条腿) |
地图铺完了。接下来换成人的视角:拿着这张地图,一步一步找断点。
二、四大故障场景:按部件的排查路径
2.0 排障第一分钟:先分诊,再进舱
中篇部署最后那份”全身体检”清单,排障时同样是第一入口——六条命令把 M-LAG 各部件的状态全部翻出来,排障时再加第七条看最近告警:
1 | display dfs-group 1 m-lag # ① 配对 / 心跳 / 主备 |
体检跑完,拿现象对分诊表,直奔对应小节:
| 现象 | 第一怀疑 | 进哪节 |
|---|---|---|
| 固定一批主机 / 连接不通,另一批正常 | 单台设备的北向路径 | 2.2 |
| 某个 VLAN 或某类业务”一半通” | 两端配置不一致 | 2.1 |
| 服务器侧单腿 / 丢包,m-lag brief 里有 inactive | 成员口 | 2.1 |
| 一台设备管理不可达 | 整机故障,或只是管理网 | 2.3 |
| error-down 告警刷屏,但业务基本正常 | peer-link 断,裁决已生效 | 2.4 |
| MAC 漂移告警 + 业务大面积混乱 | 真脑裂 | 2.4 |
| peer-link 流量水位异常升高 | 某处在绕行,顺藤摸瓜 | 2.1 / 2.2 |
分诊的底层逻辑还是心法一:**先分”全断还是半断”**。半断(固定一半不通)几乎必然指向”两台之一”的路径;全断才去怀疑两台的共性问题(网关配置、下游设备、或脑裂之后又叠了二次故障)。
2.1 部件一:成员口——统一的脸缺了半边
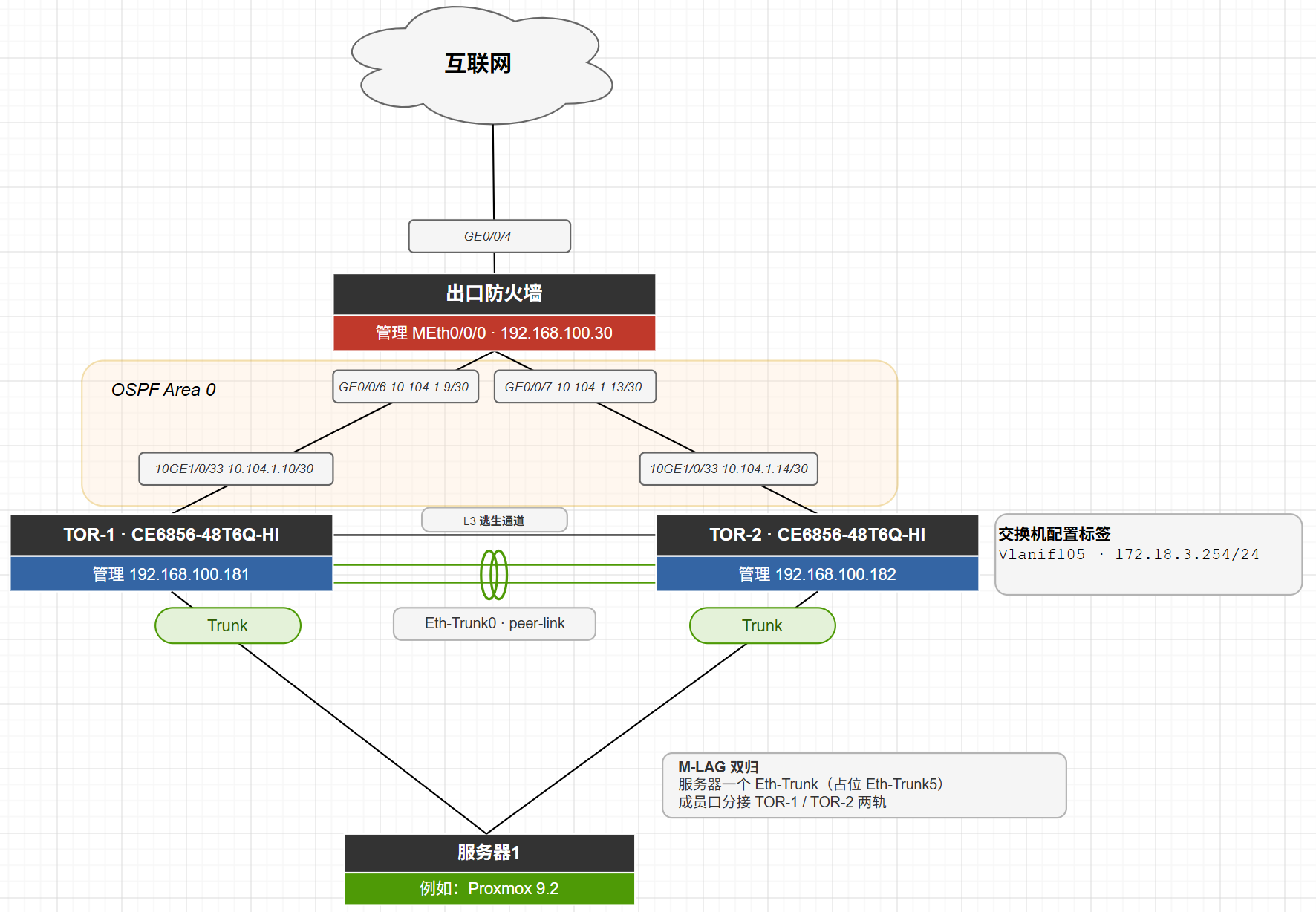
故障画像:服务器侧丢包或只剩单腿带宽;监控里某台服务器的流量全压在一条链路上;或者新绑的 m-lag 迟迟起不来。
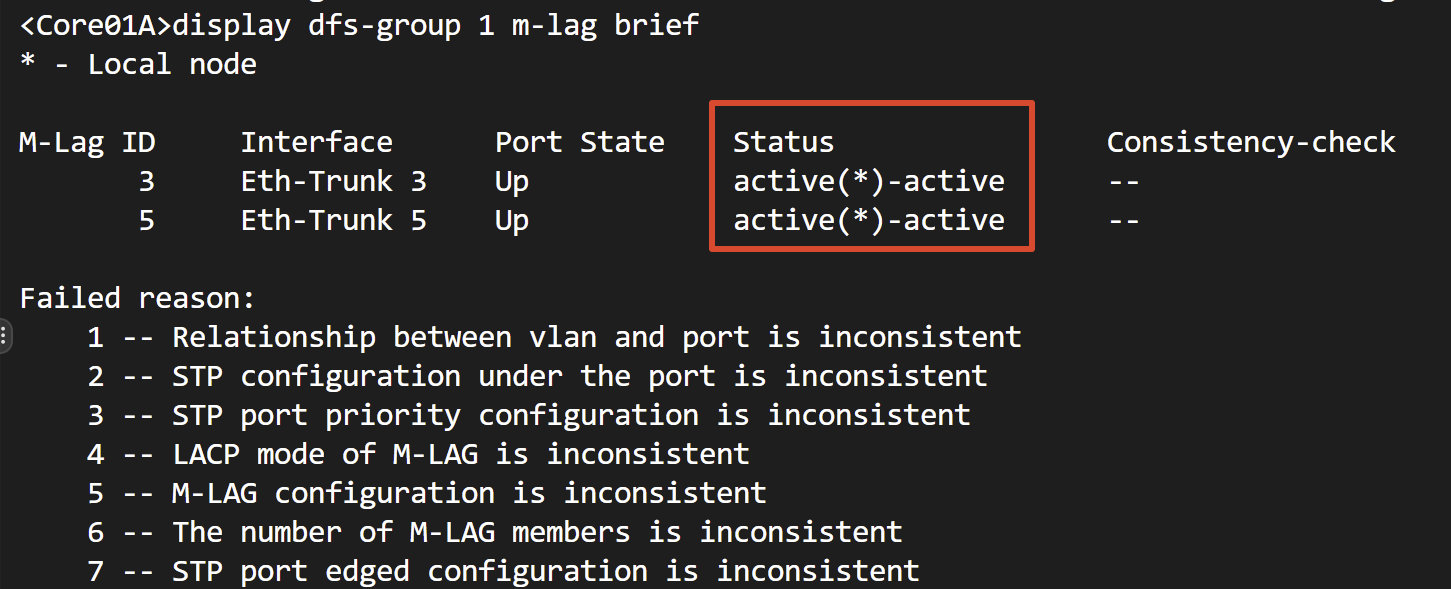
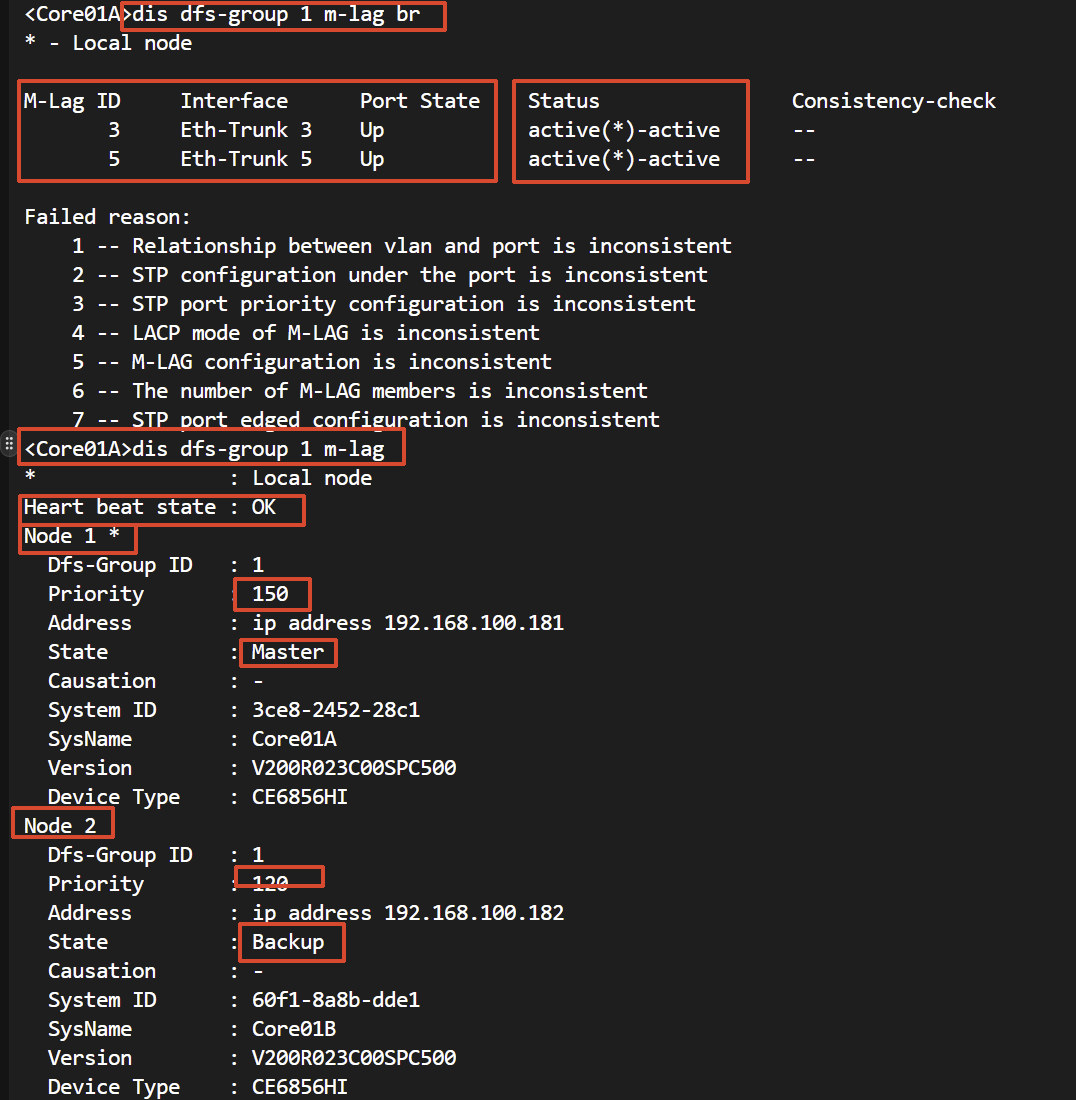
第一步,看脸。 display dfs-group 1 m-lag brief,盯 Status 列——中篇讲过它的格式是”本端-对端”,回答的问题是:这张脸的两半,各自在不在转发?
active(*)-active:双活正常,成员口没毛病,回分诊表换方向;active(*)-inactive:对端那一半没在转——登对端设备,同样的命令,看它自己怎么解释;- 本端 Port State 为 Down:本端聚合口自己没起来,进第二步。
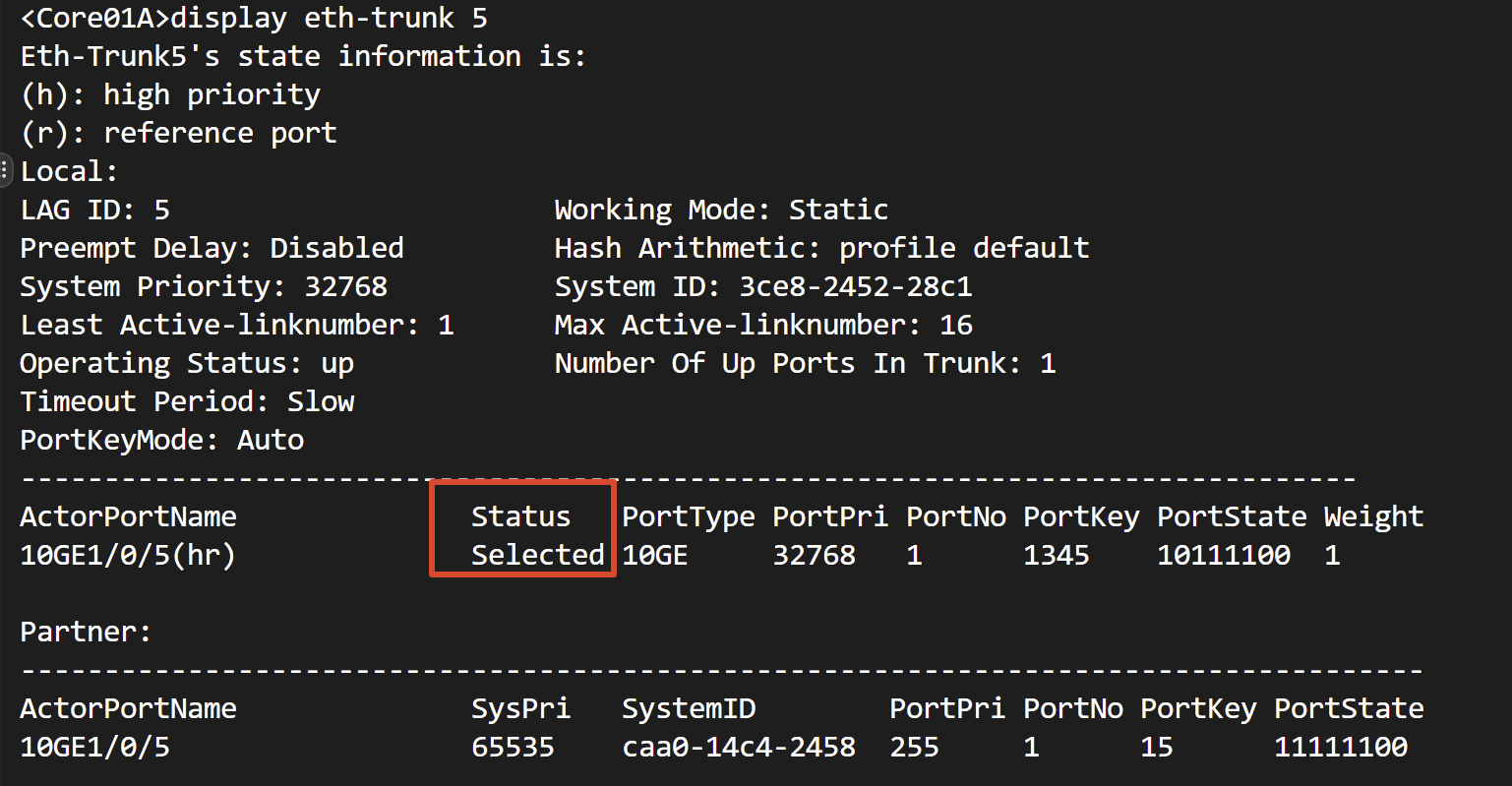
第二步,查腿。 display eth-trunk 5,看物理成员的状态:
- 物理口 Down:线、光模块、对端网卡——老老实实查物理层,
display interface 10GE1/0/5看 error / CRC 计数是否在增长; - 物理口 Up 但成员 Unselected:LACP 没协商上。十有八九出在服务器侧的 bond 模式——没起 802.3ad(LACP),或者一端手工聚合、一端
mode lacp-static。到服务器上cat /proc/net/bonding/bond0对照 LACP 协商状态,两端必须都是 LACP。
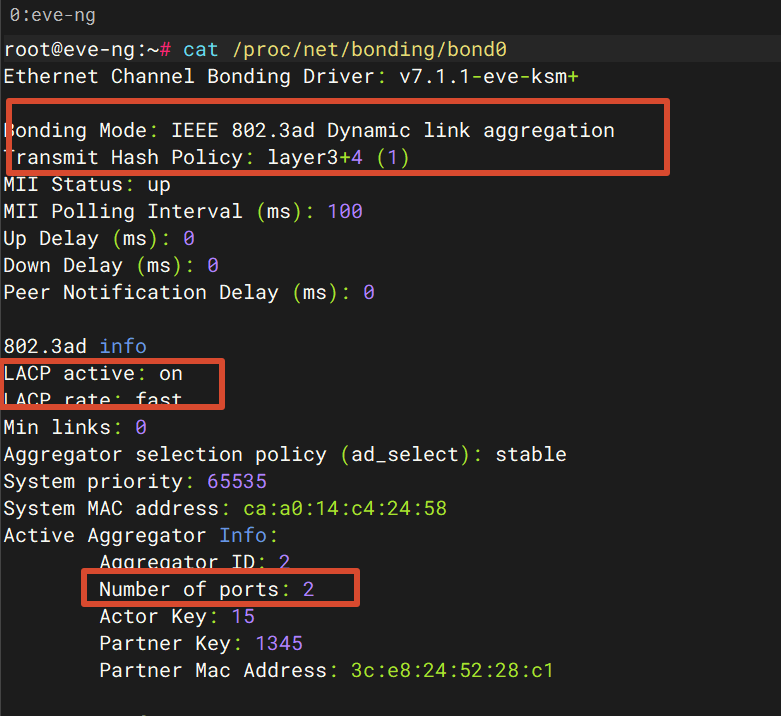
第三步,对一致性。 口都 Up、Status 也是 active-active,但某个 VLAN 或某类业务就是”一半通”?这就是中篇按下不表的 Failed reason 清单兑现的时刻。display dfs-group 1 m-lag brief 的 Consistency-check 列出现编号时,对照回显下方的枚举表定位;display dfs-group consistency-check status 看两台比对的详情。
七个编号逐条翻译:
| 编号 | 官方描述(回显原文) | 说人话 | 典型成因与后果 |
|---|---|---|---|
| 1 | Relationship between vlan and port is inconsistent | 两台成员口的 VLAN 放行清单不一致 | 变更只在一台加了 VLAN;该 VLAN 的流量 hash 到没放行的那台就丢——**”一半通”的头号来源** |
| 2 | STP configuration under the port is inconsistent | 端口下的 STP 配置不一致 | 一台改了端口 STP 参数没同步;两台对外的生成树视图不一致,极端时阻塞或环路 |
| 3 | STP port priority configuration is inconsistent | STP 端口优先级不一致 | 同上,属于”演出服穿得不一样” |
| 4 | LACP mode of M-LAG is inconsistent | 两台聚合模式不一致 | 一台 lacp-static、一台手工负载分担;协商行为不同,可能一侧成员 Unselected |
| 5 | M-LAG configuration is inconsistent | M-LAG 绑定配置不一致 | dfs-group / m-lag 相关参数两台没对齐 |
| 6 | The number of M-LAG members is inconsistent | 两端物理成员数不一致 | 一台绑两条、一台绑一条;平时能跑,但容量不对称,断腿时裕量不足 |
| 7 | STP port edged configuration is inconsistent | 边缘端口配置不一致 | 一台配了 stp edged-port enable、一台没配 |
一句话记法:1、4、5 影响”通不通”,2、3、7 影响”生成树这场戏演不演得齐”,6 影响”扛不扛得住”。 修法全部一样:把两台配置 diff 到一致,改完再跑一遍一致性检查。
第四步,验表项。 成员口故障期间,display mac-address vlan 105 里该服务器的 MAC 应指向 Eth-Trunk0(peer-link)——这正是 1.4 节说的”MAC 表改指 peer-link”,说明绕行机制在正常工作;故障恢复后,表项应指回 Eth-Trunk5。恢复后表项仍指着 peer-link,才是真异常——通常意味着 LACP 并没有真正协商成功,回第二步。
处置提醒:成员口的主备”故障恢复后不回切”是设计(上篇场景二)——升主的继续当主,恢复的甘当备;但 MAC 表项会指回本地口,流量照走本地。别把”角色没有翻回来”当成故障去”修”。
2.2 部件二:上行与逃生链路——北向的半黑洞
故障画像:心法一的标准现象——固定一批主机或连接对外不通、另一批完好;或者业务都通,但一半流量时延变大(说明在绕行)。而服务器侧毫无告警——LACP 探测的是成员链路本身,永远探不到交换机身后的断链。
第一步,数邻居。 两台交换机分别执行 display ospf peer brief。正常时每台该有 2 个 Full 邻居——防火墙(经 10GE1/0/33)加对端交换机(经逃生链路 10GE1/0/40)。哪台少了防火墙那个邻居,哪台的上行断了。 这比从服务器抓五元组倒推 hash 快得多——先锁设备,再回头对流。
第二步,看绕行。 在断了上行的那台上,查去北向的路由(以防火墙另一侧的互联网段为例):
1 | display ip routing-table 10.104.1.12 |
- 看到下一跳 10.104.1.18、出接口 10GE1/0/40、cost 101:逃生路由已经上位,流量在绕行——业务其实没断,只是路径多了一跳。接下来可以安心修物理链路;
- 查无此路由:黑洞进行时,hash 到这台的那一半流量正在被静默丢弃。先止血,再治病——看下一步。
第三步,止血(黑洞场景专用)。 最快的止血手段不是抢修上行,而是把这台的 M-LAG 成员口 shutdown:服务器侧 LACP 秒级把全部流量压到另一台——用”暂时牺牲双活”换”业务全通”。等上行修好、OSPF 邻居回到 Full 之后,再把成员口放开。顺序千万别反:先放成员口、上行却还没通,等于亲手把一半流量再次引进黑洞。
注意:本操作恰好是华为官方推荐的 Monitor Link 功能的人工执行版本
手动 shutdown 是急救,生产环境的最佳实践是配置 Monitor Link。把上行口和 M-LAG 成员口做联动:上行链路一旦故障,设备自动 down 掉下联成员口,服务器侧 LACP 随即把流量切到另一台,黑洞在形成之前就被掐灭,不再依赖值班工程师的手速。它解决的正是黑洞的根因:下游感知不到上游的死亡——服务器只看得见自己那条腿是 Up 的,看不见这条腿背后的上行已断;Monitor Link 把”上行死了”翻译成”下联口 down”,让故障信号穿透设备传递到服务器。
1 | # SwitchA(SwitchB 同理) |
第四步,修物理。 display interface 10GE1/0/33 看物理层线索:CRC / error 计数持续增长指向线缆或模块;光口再核对光模块收发功率是否在正常范围。对端防火墙口同步检查。
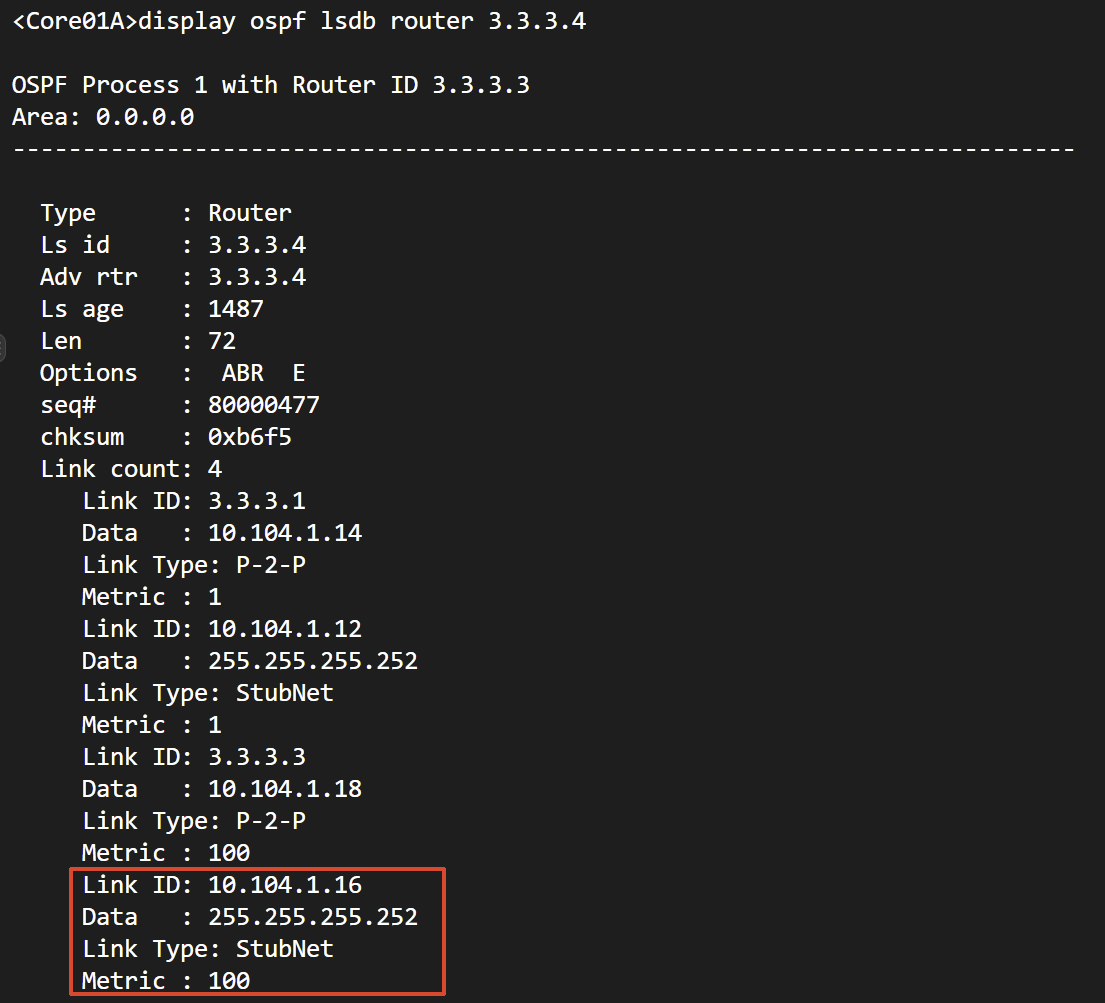
第五步,验收敛与回归。 链路恢复后,三处对表:本机的防火墙邻居回到 Full;防火墙侧 display ip routing-table 172.18.3.0 回到两条 ECMP;本机那条经逃生链路的绕行路由从路由表退位——它仍躺在 LSDB 里待命(在两台交换机上输入display ospf lsdb router 3.3.3.3以及display ospf lsdb router 3.3.3.4 均可见)。”平时隐身、故障上位、恢复退位”的三段式(中篇 1.9),在这里完成闭环验证。
一个前置问题:如果第一步就发现,这台交换机从来就没有过”逃生链路邻居”——那不是故障,是设计缺位。直接看坑一。
2.3 部件三:整机——难的不是宕机,是复活
故障画像:一台设备管理不可达;业务侧通常只有秒级抖动(前提是上、中篇的每一步都配对了),甚至完全无感。整机故障的排查重点,往往不在”宕机的那一刻”,而在”复活的那几分钟”。
第一步,分清”它死了”还是”我瞎了”。 管理不可达不等于设备宕机——可能只是管理网断了。上存活的那台看 display dfs-group 1 m-lag:对端 Node 信息还在、Heart beat state 还是 OK,说明对端还活着、只是你的管理路径断了;对端 Node 消失、心跳异常,才是真宕机。DAD 心跳在这里兼职了一次”生死探测器”。
注意:
dis dfs-group 1 m-lag(不带 brief):看”节点配对关系”dis dfs-group 1 m-lag brief:看”成员口状态”
第二步,确认单机独扛。 在存活台上:display dfs-group 1 m-lag brief 各 m-lag 本端 active;display ospf peer brief 北向邻居正常;display interface brief 重点看上行口和成员口的带宽利用率——单台此刻扛着全量,水位就是最要紧的健康灯。
第三步,复活阶段管住手。 故障机重新上电后,恢复有严格顺序(上篇场景三讲过为什么):peer-link 先 Up,DFS 重新配对,全部表项经 peer-link 灌给它,成员口最后才放开——华为缺省在 peer-link 恢复后,处于 error-down 的 M-LAG 接口等 240 秒再自动恢复,留的就是表项同步的时间。这 240 秒里成员口显示 down,是保护,不是故障;display error-down recovery 可以看到哪些接口处于 error-down 及其自动恢复信息。别用 undo shutdown 去”抢救”——坑四专门讲这只手怎么闯祸。
第四步,复活后验收。 四处对表:display dfs-group 1 m-lag 配对恢复、一主一备;display mac-address / display arp 两台表项规模相当(说明同步追平);display dfs-group 1 m-lag brief 回到 active-active;display dfs-group consistency-check status 再跑一遍——设备换件或升级之后,配置漂移并不罕见。
角色说明:整机故障恢复后,DFS 按优先级重新协商——A(priority 150)恢复后仍是主。注意这与成员口的”不回切”不在一个轴上:成员口的主备不抢占,DFS 角色缺省按优先级归位;若不希望角色来回切换,中篇 2.3 提过 dfs-group state switchover disable。
2.4 部件四:peer-link 与 DAD——裁决与脑裂
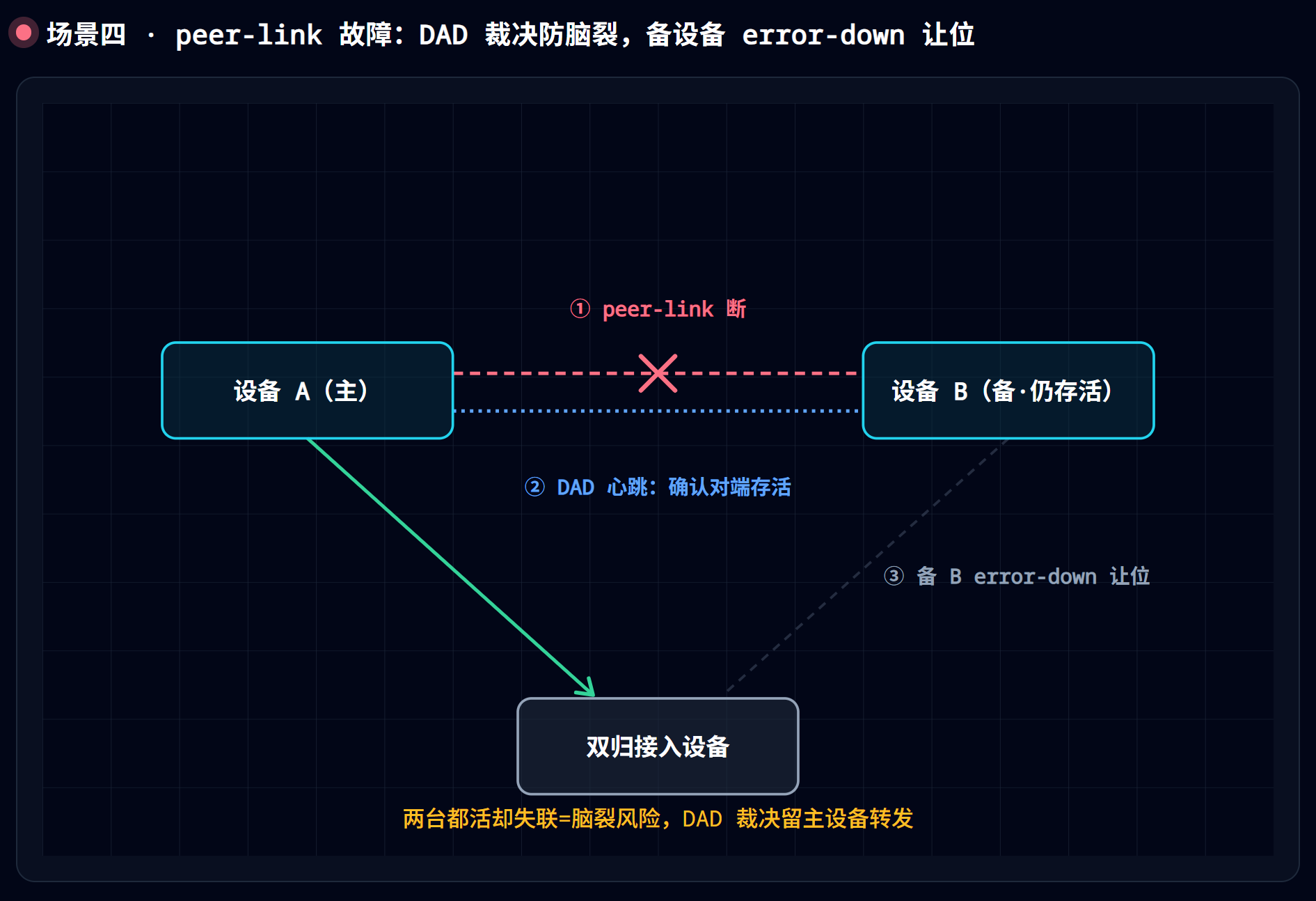
peer-link 故障有两副面孔,严重程度天差地别。排查的第一步,永远是分清自己站在哪一副面孔里。
面孔一:裁决生效——告警吓人,业务没事
peer-link 断了,但 DAD 还活着。
画像:error-down 告警刷屏(备机一整片接口 down),但业务基本无感——主机在独扛全量。
排查路径:
display dfs-group 1 peer-link显示 Down;display dfs-group 1 m-lag里Heart beat state仍是 OK——裁决已经按剧本执行:DAD 确认了对端还活着,备机把业务口 error-down、主动退场,把”两张脸同时说话”的风险掐灭在了萌芽里。此时该做的是修 peer-link,而不是到处拉端口。- 备机上
display error-down recovery列出被关的口——应该只有业务口;管理口、peer-link 口以及配了m-lag unpaired-port reserved的口不在其列。裁判口绝不能被关,这是中篇画下的红线;如果发现 DAD 心跳口也躺在 error-down 名单里,说明红线早就被踩了,脑裂只是还没轮到你。 - 查 peer-link 断因:
display eth-trunk 0。两条物理成员同时 Down?查两条线的共同故障点——同一块单板、同一条线槽、同一套波分,这正是中篇要求”框式设备成员口跨板部署”要防的事。而如果只断了一条成员就触发了裁决——说明 peer-link 当初只配了单物理成员,这是”假性脑裂”(上篇讲 peer-link 必须聚合的原因),把冗余成员补上。 - 恢复:peer-link Up 之后,备机 error-down 的 M-LAG 口 240 秒后自动回。全程不需要人工 undo shutdown。
面孔二:真脑裂——最凶险的局面
peer-link 断了,DAD 也断了。
画像:MAC 漂移(MAC flapping)类告警反复出现、下游 ARP 时对时错、业务大面积时断时续。两台各自查 display dfs-group 1 m-lag,都只看得到自己、都认为自己该在岗,心跳状态异常——裁判失联,没人退场,两台顶着同一个桥 MAC、同一个网关 IP 和虚拟 MAC 同时对外说话,下游的 MAC 表在两个端口之间反复横跳。
排查路径(先止血,后治病):
- 人工替 DAD 完成裁决。 选定一台(通常选备机,或上行状态更差的那台),把它的 M-LAG 成员口和上行口 shutdown——手动让它退场。业务立刻归于一台,先稳定下来。
- 治病。 分别修 DAD 和 peer-link,并且必须回答一个问题:它们为什么会同时断? 九成的答案是坑二——心跳和 peer-link 在物理上共了路径,”裁判和被裁判的同归于尽”。
- 恢复顺序:先恢复 DAD,再恢复 peer-link,最后放开被 shutdown 的口——保证任何时刻,裁判都先于选手到场。
- 复盘必查三件事:DAD 是否物理独立于 peer-link(红线);peer-link 是否聚合了多条物理成员;
dual-active detection enhanced enable是否在配——它兜的是”peer-link 断了之后、主机又宕了”的二次故障:备机凭心跳(HB DFS)感知主机故障,自动拉起被 error-down 的口接管业务(上篇场景四第 5 条)。
三、七个生产环境经典坑
场景排查讲的是”部件坏了怎么查”,这一部分讲的是另一类问题:部件没坏,是人挖的坑——设计时省掉的一条链路、变更时漏改的一台设备、认知里缺的一块拼图。七个坑,每个都按”现象、根因、一眼定位、修与防”四段展开。
坑一:没配逃生链路——“时通时不通”的北向半黑洞
现象:凌晨 SW1 的上行光模块故障。北向 OSPF 秒级收敛,防火墙自动把路由切到 SW2,监控大盘一片绿。可从早高峰开始,工单雪片一样飞来:”我这台虚机上不了外网,旁边那台好好的。”有人重启了虚机——部分连接”居然好了”,故障从此被贴上”玄学”标签。
根因:服务器的 LACP 探测的是自己到交换机的成员链路,永远探不到交换机身后的上行断链——SW1 的成员口还是 Up 的,hash 照旧把一半的流送进 SW1;而 SW1 去防火墙的路由已随邻居消失,又没有逃生链路给它一条”经 SW2 绕行”的路,这一半流量被静默丢弃。它只黑一半、不会自愈、持续到人工干预为止(中篇 1.9 推演过帧级细节)。至于”重启居然好了”:重启后连接的源端口变了,一部分流的 hash 换了边——不是修好了,是换了批受害者。
一眼定位:SW1 上 display ip routing-table 查北向网段——查无路由,黑洞实锤。
修与防:止血按 2.2 第三步,shutdown 该台成员口;根治按中篇 1.9 补全逃生链路。预防只有一个硬标准:上线前做拔线演练——把每条上行轮流断一遍,业务无损才算验收通过。逃生链路是那种”平时看不见、缺了才要命”的配置,不演练,你永远不知道它到底在不在。
坑二:DAD 心跳借道 peer-link——裁判和被裁判共命运
现象:平时岁月静好,什么异常都测不出来。直到 peer-link 真断的那一天——心跳同时消失,裁决失灵,直接跳进 2.4 的面孔二:真脑裂。
根因:用 VLANIF 做 DAD,而 peer-link 缺省放行所有 VLAN——心跳报文平时就安安静静地走在 peer-link 上,两者物理上共了命运。这是最阴的一类坑:它平时完全无症状,只在最需要裁判的那一刻缺席。
一眼定位:审配置,两问。一问 dfs-group 里的 source ip 落在哪个接口上——是 VLANIF 就要警惕;二问该 VLAN 在 peer-link 的 Eth-Trunk0 上有没有被 exclude。两问答案凑成”VLANIF 加 没排除”,坑已就位。
修与防:首选带外管理口或独立三层口(undo portswitch)承载 DAD——纯三层转发,和 peer-link 毫无交集;万不得已用 VLANIF,必须在 peer-link 上 port vlan exclude 掉心跳 VLAN。这是中篇 1.3 的红线,值得每季度巡检时都重新审一遍——因为后来的变更可能悄悄把它改坏。
坑三:变更只改了一台——一半流量凭空消失
现象:周五晚上新业务要加 VLAN 206,值班同事在 SwitchA 上加了放行,SwitchB “下周再说”。周一业务上线:”一半的机器 ping 不通网关。”
根因:M-LAG 的成员口是”两台合演的一张脸”,VLAN 只在一台放行,等于这张脸半边能听见、半边聋——hash 到 SwitchB 的流量,在成员口就被 VLAN 过滤丢弃。心法一的现象学再次登场:固定一半、绝不随机。
一眼定位:display dfs-group 1 m-lag brief 的 Consistency-check 列出现编号 1(VLAN 与端口关系不一致);display dfs-group consistency-check status 看比对详情。
修与防:对齐两台的 port trunk allow-pass。预防是一条纪律:M-LAG 的变更单位永远是”一对”,不存在”只改一台”的合法变更;改完必跑一致性检查——中篇部署体检的第②条,也是每一次变更的最后一步。
坑四:把 error-down 当端口故障——240 秒里的那双手
现象:peer-link 割接完成、链路恢复,可备机的成员口迟迟不 Up。现场同事判断”端口坏了”,一顿操作猛如虎:shutdown / undo shutdown、拔插光模块,甚至开始讨论重启设备。
根因:peer-link 恢复后,M-LAG 接口的 error-down 缺省再保持 240 秒才自动恢复——这段时间留给表项经 peer-link 同步。一台表项空白的设备提前上岗,等着它的就是黑洞和环路(上篇场景三的”先同步好、再上岗”)。手工强拉端口,恰恰是绕过了这道保护。
一眼定位:display error-down recovery——接口躺在里面、原因指向 m-lag,就是保护期,不是故障。
修与防:等。把”240 秒”写进应急预案和告警备注,让每个值班的人都知道这四分钟是设计出来的冷静期。真有业务理由要调整恢复时长,按设备手册的正规命令改参数,而不是用手去拉端口。
坑五:一台 network、一台 import-route——ECMP 悄悄失效
现象:说不上故障,但监控里两条上行的流量一边倒:北向下行流量全走 SW1,SW2 那条常年闲置。更隐蔽的版本是割接后才出现——没人发现,直到某天 SW1 上行一断,才惊觉”怎么只有一条路”。
根因:双人分工配置,一台用 network 宣告业务网段,一台用 import-route 引入直连。OSPF 里区域内路由严格优于外部路由,类型不同的两条路由永远不做等价——防火墙的路由表里只剩一条,ECMP 无声失效。这是中篇 1.8 点过名的”双人分工头号坑”,值得单独立案,因为它的杀伤力在于安静:业务一切正常,只是冗余和一半带宽都已不在。
一眼定位:防火墙上 display ip routing-table 172.18.3.0——正常该有两个下一跳,只剩一个就中招;再到两台交换机对 OSPF 配置,看宣告方式是否一致。
修与防:统一用 network 宣告。预防靠约定先行:分工配置前,先把”宣告方式、区域划分、cost 基准”写成一页纸对齐,再各自开工。
坑六:漏配 silent-interface——告警噪音淹没真故障
现象:日志里每隔几秒刷一条地址冲突类告警,display ospf 1 error 里 IP: received my own packet 的计数一路疯涨。值班同事从”每条都看”变成”全部免疫”——三个月后一次真故障的前兆告警,就淹死在这片噪音里。
根因:两台交换机的 VLANIF105 配着同一个网关 IP,而 network 172.18.3.0 0.0.0.255 顺手把 OSPF 使能到了这个接口上——各自发出的 Hello 经 peer-link 送到对方手上,源地址与本机接口地址一模一样,只能按非法报文丢弃并记日志。邻居永远建不起来,告警却永远刷下去。
一眼定位:display ospf 1 error 看 received my own packet 计数是否持续增长。
修与防:OSPF 进程下 silent-interface Vlanif105——保留网段宣告、掐掉接口上的协议报文收发。中篇 1.8 的原话:双活网关跑 OSPF,这条不是可选优化,是必配项。更普遍的教训是:告警的信噪比本身就是可靠性的一部分——一条你打算永远忽略的告警,要么修掉它,否则总有一天它会替你掩护一次真故障。
坑七:有状态设备撞上双活的非对称——回程包去哪了
现象:网络里新串了一台做会话检查的设备(防火墙、LB、NAT 网关)之后,TCP 业务开始”随机”超时或被重置;抓包发现去程正常、回程凭空消失。ICMP 却往往是通的——排障方向因此被带偏很久。
根因:1.2 节第 6 跳埋的伏笔兑现。双活网关加 per-flow hash 加 ECMP,意味着同一条流的去程和回程,天然可能经过不同的交换机——交换机无状态,无所谓;但有状态设备要求”来回都从我过,而且我认识这条会话”。典型翻车姿势有二:两台防火墙各自上联一台交换机、彼此不做会话同步——去程经 FW1 建了会话,回程被 hash 送进 FW2,FW2 查无会话、按非法报文丢弃;或者把防火墙透明串接在单侧链路上,只看得见一半的流量。至于 ICMP 为什么常常幸免:它的 hash 输入没有端口,来回路径恰好恒定的概率高得多——这正是”ping 通了不代表业务通”的一个标准注脚。
本系列的组网为什么没事:两台交换机的两条北向路径,都终结在同一台防火墙上——来回无论怎么绕,最终都经过它,会话表始终完整。非对称只发生在无状态的交换机之间,无害。
一眼定位:有状态设备上看丢包统计与会话命中情况;两端同时抓包,比对去程和回程的实际路径。
修与防:三选一。让有状态设备只部署在”来回必经的汇聚点”(本系列的做法);或者双机部署时做会话同步(防火墙双机热备);或者用策略强制”源进源出”保证对称。预防落在架构评审:凡新增有状态节点,先画一张”来回路径图”再上线——在双活的世界里,”包能过去”和”包能回来经过同一张会话表”,是两个必须分别验证的命题。
总结:排障排的,是那句话还成不成立
三部曲到这里收官。回头看:
- 原理篇回答”为什么”——为什么要演成一台,靠什么演;
- 部署篇回答”怎么搭”——按依赖顺序把戏台搭起来;
- 排障篇回答”怎么救”——戏穿帮了,沿着流量走一遍,找到第一处对不上台词的地方。
排障没有玄学。转发是确定性系统,每个包在每一跳的去向都由表项写死——沿着流量走一遍,逐跳对表,断点即故障点。M-LAG 只是在这条通则上多给了两条心法:”一半不通”先问哪一半,peer-link 的流量水位就是体温计。
而四大场景、七个坑,说到底都在检验同一句话——
对外一台,对内两台;同步靠 peer-link,裁决靠 DAD。
同步断了,看裁决;裁决也失灵了,人来当裁判。只要这句话还成立,这台”演出来的设备”,对外就永远只有一张脸。
(M-LAG 三部曲·全系列完)