M-LAG(上·原理篇):不是把两台交换机合并成一台,而是让它们对外”演”成一台
数据中心里最不能接受的一个字,就是”断”。
为了不断,我们让服务器双上联;可双上联本身又会带来环路、带宽浪费、网关单点一堆新麻烦。业界为此折腾了整整三代方案,最后才收敛到今天的主流——M-LAG。
这篇我们干三件事:先讲清 M-LAG 的前生今世,看它到底补上了前两代的哪块短板;再把它的底层心智模型和各类接口的职责一个个拆开;最后讲它真正的看家本领——流量在正常和故障下到底怎么走。
先把一句话焊进脑子,后面所有机制都是它的注脚:
M-LAG 不是把两台设备合并成一台(那是堆叠),而是让两台控制平面完全独立的设备,对下游”演”成一台。
一、前生今世:从”主备”到”双活”,从”单脑”到”双脑”
一切的起点:一根线,迟早会断
一台服务器、一台接入交换机,如果只往上接一台设备,那台设备就是它的命门——设备一挂、链路一断、甚至升级重启,它就下线了。
所以第一反应很朴素:双上联。往上接两台设备,一台倒了还有另一台。
双上联不是免费的午餐
可你一旦拉出第二条上联,三个新问题立刻冒出来——它们恰好就是”高可用”真正要解决的三根支柱:
- 冗余,但要防环。 两条链路加上两台上联设备之间的互联,物理上就成了一个闭合路径。二层以太帧没有 TTL,广播/未知单播又默认泛洪,闭合路径 + 无 TTL + 泛洪 = 广播风暴。冗余不能以成环为代价。
- 双活,不浪费。 你掏钱买了两条链路、两台设备,不能让一条干活、一条常年睡觉当备胎。
- 切换要快。 真出故障,得秒级甚至毫秒级切过去。这就是在缩小 MTTR(平均修复时间)——可用度 = MTBF /(MTBF + MTTR),电信级的 99.999% 意味着每年故障中断不超过 5 分钟,这正是数据中心老板要的东西。

判断一代方案够不够格,就看这三条满足了几条。我们顺着这把尺子往下看。
第一代:STP + VRRP —— 能用,但一半的钱打了水漂
这是最传统的组合,两个标准协议各管一层:
- STP(二层防环):靠 block 掉一条链路来打断环路。问题是,被 block 的那条链路平时不传任何数据,纯备胎,只在另一条断了才顶上。
- VRRP(三层网关冗余):两台设备共用一个虚拟 IP/MAC 当网关,一主一备。问题是默认主备,网关流量只走 Master,Backup 干等着。
合起来看:环防住了、网关冗余了,但二层一条链路被 block、三层网关一台闲置——一半带宽常年睡觉;而且 STP 收敛以秒计,故障切换不够快。
一句话:第一代是主备思维,安全,但浪费,三根支柱只勉强占了”冗余”一条。
第二代:堆叠 —— 干脆把两台”焊成”一台
既然两台设备各自为政会成环,那就把它们合并成一台逻辑设备:一个大脑、一个管理 IP,对外就是一台。
这一招很漂亮。服务器只要做一个普通的链路聚合(LACP),两条线打到”同一台”逻辑设备上——逻辑上根本没有环,两条线都能转发(双活),配置还简单到只配一个 IP。三根支柱里的”防环””双活”一举拿下。
但它的代价是致命的:控制平面合一。几台设备共用一个大脑,大脑一抽风(软件故障),或者你升级系统时手一抖,整个堆叠系统集体罢工。业界虽有 ISSU(不中断业务升级)这类机制,但用在”单一控制平面”上限制多、风险大,很多场景仍要重启整套系统。
一句话:第二代用单脑换来了双活和简单,却把所有鸡蛋放进了一个篮子。
第三代:M-LAG —— 既要双活,又不肯把命交给一个大脑
M-LAG 的野心很明确:保留堆叠的”双活”和”对外像一台”,但把那个致命的单点——合一的控制平面——拆开。
做法是这样的:两台设备各有各的操作系统、各有各的大脑(双主、地位平等),但通过一条”私线”——peer-link——串通好口供,对下游统一用同一个 LACP 系统号说话。下游一看:”哦,上面就一台逻辑交换机嘛,我发 LACP 报文给它,它也回我,没毛病。”
于是:
- 对外是一台:下游做的就是普通链路聚合(LACP),双活、防环,配置毫无负担;
- 对内是两台:一台崩溃或升级,另一台有自己独立的大脑,毫无影响。
这就是数据中心现在的主流形态(华为 M-LAG、思科 vPC、H3C DRNI 都是这一类)。
三代对照:核心就两根轴
| 方案 | 是否双活 | 控制平面是否独立 | 升级/故障影响 | 典型场景 |
|---|---|---|---|---|
| STP + VRRP | 否(主备,一半闲置) | 各自独立,但靠 STP/VRRP 拼凑 | 收敛慢、有抖动 | 传统园区 |
| 堆叠 | 是(100% 利用) | 否(合一,单点) | 可能整体中断 | 园区接入/汇聚 |
| M-LAG | 是(100% 利用) | 是(双脑独立) | 接力升级,业务 0 中断 | 数据中心、金融/医疗核心 |
看清这张表,M-LAG 落到实处的三个硬优点也就清楚了:
- 控制平面解耦:一台控制面崩了,另一台毫不知情,流量瞬间切过去,业务真正 0 中断;
- 升级无感:玩”接力赛”——先升 A,B 扛全部流量;A 升好上线,再升 B,全程不断;
- 天然防环 + 满带宽:配合下游做 LACP 聚合,接口上不再有 STP 的 Block 端口,带宽利用率 100%。
二、底层心智模型:每个接口存在的理由
先分清”控制平面”和”转发平面”
要真正看懂 M-LAG,得先知道一台交换机内部其实有两套系统:
- 控制平面(大脑):跑协议、做决策、生成表项(路由表、MAC 表、ARP 表、STP 计算结果)。它靠 CPU 跑软件,慢。
- 转发平面(肌肉),也叫数据平面:拿大脑算好的表项,以线速把数据包搬出去。它靠 ASIC 芯片,快。
| 控制平面(大脑) | 转发平面(肌肉) | |
|---|---|---|
| 职责 | 跑协议、做决策、生成表项 | 按表项以线速搬数据包 |
| 例子 | 路由表 / MAC 表 / ARP / STP 计算 | 芯片查表转发 |
| 速度 | 慢(软件、CPU) | 快(硬件、线速) |
| 堆叠怎么处理 | 合一(单脑,单点风险) | 统一 |
| M-LAG 怎么处理 | 各自独立(双脑,互不影响) | 经 peer-link 同步表项,对外表现一致 |
这张表就是整个 M-LAG 的地基:堆叠是把两个控制平面合一,M-LAG 是保留两个独立控制平面、只让两个转发平面表现得像一个。 “对外一台、对内两台”翻译成精确的话就是——两个独立的大脑 + 一对协同一致的肌肉。而 peer-link 同步的,正是大脑算出来的决策结果:表项。
那这两个平面各自”转”的是什么?记住一个判别法:看这个包是”借道过路的”,还是”发给设备自己、或设备自己发出的”。
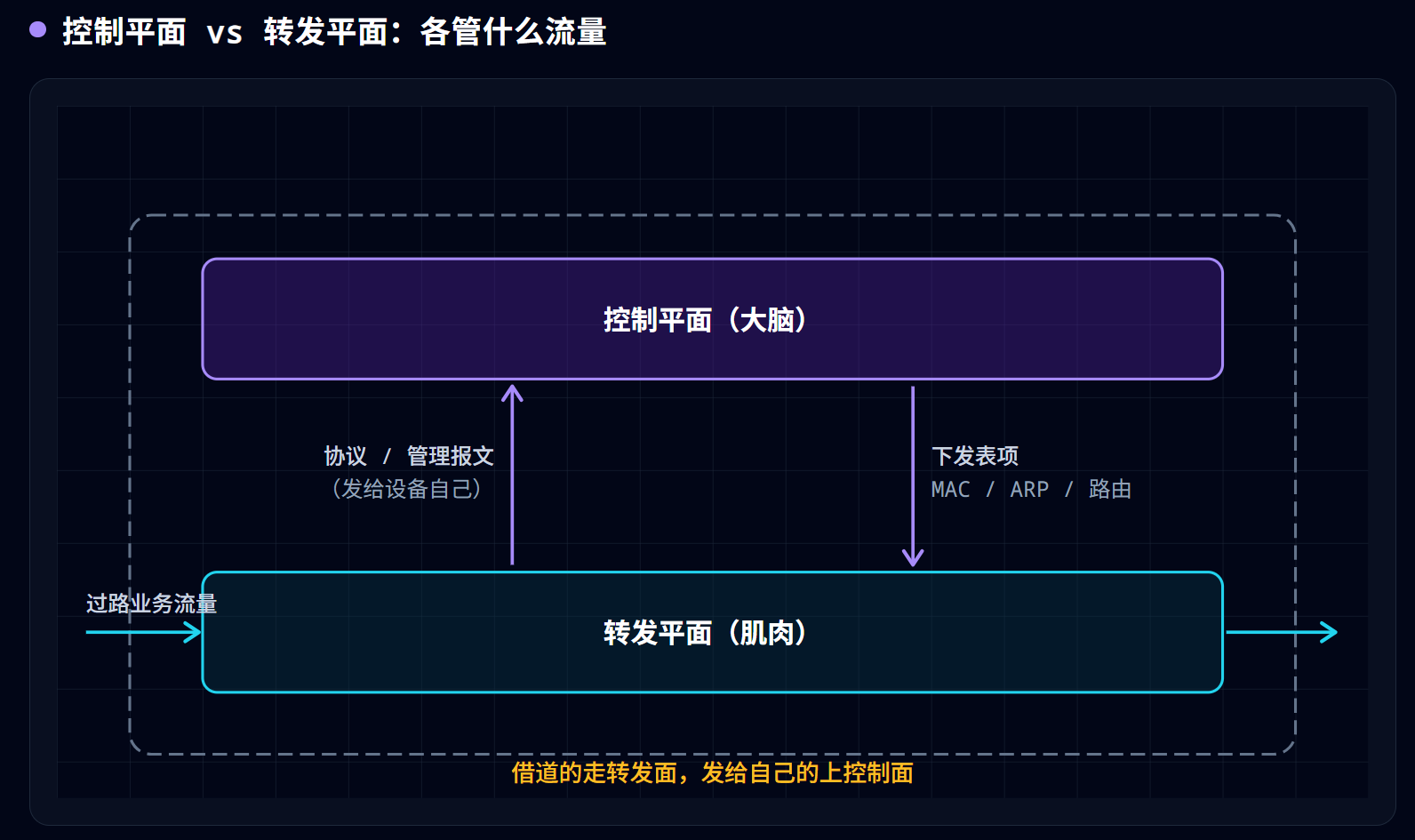
转发平面,转的是”过路的业务流量”。 别人的包从一个口进、要从另一个口出,交换机只是个中转站,不关心内容,纯靠 ASIC 硬件查表、线速搬运。数据中心里 99% 以上的包都是这类——它们只穿过转发面,碰都不碰大脑。
控制平面,处理的是”跟设备自己有关的报文”。 它严格说不做”过路转发”,而是收发并处理两类报文:一是协议报文(OSPF/BGP 路由、STP 的 BPDU、LACP、ARP、VRRP……设备靠它们和邻居”对话”),二是管理报文(SSH、SNMP、NTP、syslog……你管理设备走的就是这些)。这些报文被”上送 CPU”由控制面处理,处理的产物就是表项(MAC 表、ARP 表、路由表),再下发给转发面去转真正的业务流量。
一句话记牢:你 SSH 登录这台交换机,包是发给它自己的 → 上控制面;一台服务器 ping 另一台、流量从交换机借道而过 → 走转发面。
把那句话焊进脑子
对外一台,对内两台。 既然对内是两台独立的设备,它们之间就必须解决两件事——而 M-LAG 里所有接口和概念,都是为这两件事服务的:
- 问题一:两台独立设备,怎么时刻保持”对外一致”?(同步)→ 靠 peer-link + DFS Group
- 问题二:万一它们之间失联了,怎么不打架、不出两张脸?(裁决)→ 靠 双主检测 DAD + 保护性下线
记住”同步”和”裁决”这两条线,下面每个接口你都能对号入座。
peer-link:M-LAG 的主干,一条线干两件事
peer-link 是两台设备之间的那条”私线”,同时承担两个职责:
- 控制面同步:同步表项(MAC/ARP)、角色协商、STP 状态同步。两台设备靠它”对暗号”——左边学到了服务器的 MAC,就告诉右边”你也在表里记一笔,假装你也学到了”。
- 二层数据转发:部分东西向流量、以及故障时的绕行流量,会从这里过。注意:这里走的是二层转发,peer-link 本质上是一条二层链路——先记住这点,后面讲”三层逃生链路”时,它是关键伏笔。
为什么 peer-link 一定要高带宽、而且必须做链路聚合?两个工程要点:
- 高带宽:正常情况下业务流量基本不走 peer-link,可一旦上行口或成员口故障,大量绕行流量会突然全压上来;带宽不够就成瓶颈、丢包。所以要按”最坏情况下可能绕行的流量”来预留,通常 40G/100G 起步。
- 必须聚合:peer-link 是 M-LAG 的命脉,一旦它断了,就会触发后面要讲的脑裂裁决(备设备成员口被强制下线)——这是个高危单点。把它做成链路聚合(多条物理成员),单条物理线坏了 peer-link 整体不中断,等于给命脉本身上了冗余,避免”假性脑裂”。
DFS Group:让两台设备的”表项”保持一致
交换机靠表项做转发决策:二层看 MAC 地址表(哪个 MAC 是从哪个口学来的),三层看 ARP 表(IP ↔ MAC ↔ 出接口)。
DFS Group(动态交换服务组)干的唯一大事,就是让两台设备实时同步彼此的表项。举个例子:A 从自己的成员口学到了服务器的 MAC,它会经 peer-link 告诉 B——“这个 MAC,算你也从对应的成员口学到了”。这样无论下游的流量被 hash 到 A 还是 B,两边查表的结果都一样,就近转发,不用绕路。表项一致 → 转发行为一致 → 对外才是一张脸。
它同时负责给两台设备配对、分主备:先比角色优先级、优先级相同再比桥 MAC(值小者为主)——这是三家厂商一致的选举逻辑。
这里要破除一个最常见的误区:
正常情况下,DFS 主和备的转发行为完全一样,两台都在满负荷转发,地位平等。主备的差别,只在故障场景下才体现。
别再以为”备设备平时不干活”——“备”只是一个给故障裁决预留的身份标签。
双主检测 DAD:平时不上班的”裁判”
DAD(双主检测,也叫心跳链路)是一条三层链路。它的定位很特别:
正常情况下,DAD 不参与任何转发。它是个平时不上班的裁判。
它唯一的作用是:当 peer-link 断了、两台设备失联时,用来判断”对端到底还活着没有”。
为什么它必须独立于 peer-link?这是整个 DAD 设计的命门:
- 如果 DAD 走的就是 peer-link 本身,那 peer-link 一断,DAD 跟着断——裁判和被裁判的同归于尽,DAD 就彻底失去了存在意义。
- 所以 DAD 必须刻意走不同的物理路径(通常用带外管理口 mgmt 互联,或单独占一条物理口),避免和 peer-link “共命运”(shared fate)。
定位一句话:DAD 不是转发必需的链路,但强烈建议配置——它是”可靠性兜底”,不是”业务通路”。
M-LAG 成员口:对下游露出的那张统一的脸
主备设备上连接下游(服务器或接入交换机)的那个链路聚合口(华为叫 Eth-Trunk,推荐配成 LACP 模式),就是 M-LAG 成员口。
它就是”演成一台”对外露出的接口——下游会把两台设备各自的成员口,看成同一个聚合组里的成员。这张统一的脸在不在、会不会变成两张脸,正是后面所有故障处理的核心命题。
一个口的三种”下线”:从通用概念到 error-down
讲故障处理前,先把一个口的三种 down 分清楚,这是个通用概念:
- 物理 down:线/光模块真坏了;
- 管理 down:人为执行了
shutdown; - 保护性 down:链路本身是好的,但被系统按某种保护逻辑自动置为下线,不收不发业务流量。
第三种是我们关心的。各家叫法不同:思科叫 errdisable(error-disabled),华为叫 error-down,原理完全一致——都是”交换机软件因为某种保护机制,主动把一个好端口关掉”。它不是真坏,触发条件消失后会自动恢复 up。
在 M-LAG 里,保护性下线是”裁决之后的执行手段”:当一台设备被裁定要”让位”时,就把自己的成员口置为保护性下线(华为即 error-down),强制流量只走另一台——把”两台都对外说话”的冲突掐掉。
单向隔离:靠它破环,不靠 STP(各家同源技术)
这点极其重要,是后面流量模型的地基。
回忆环路的本质:闭合路径 + 二层帧没有 TTL + 交换机对广播/未知单播默认泛洪 = 风暴。
M-LAG 内部其实也潜伏着一条闭合路径:一份泛洪帧从成员口进了 A,经 peer-link 同步到 B,如果 B 再从自己的成员口把它泛给下游,下游就可能收到重复帧、甚至绕回来成环。
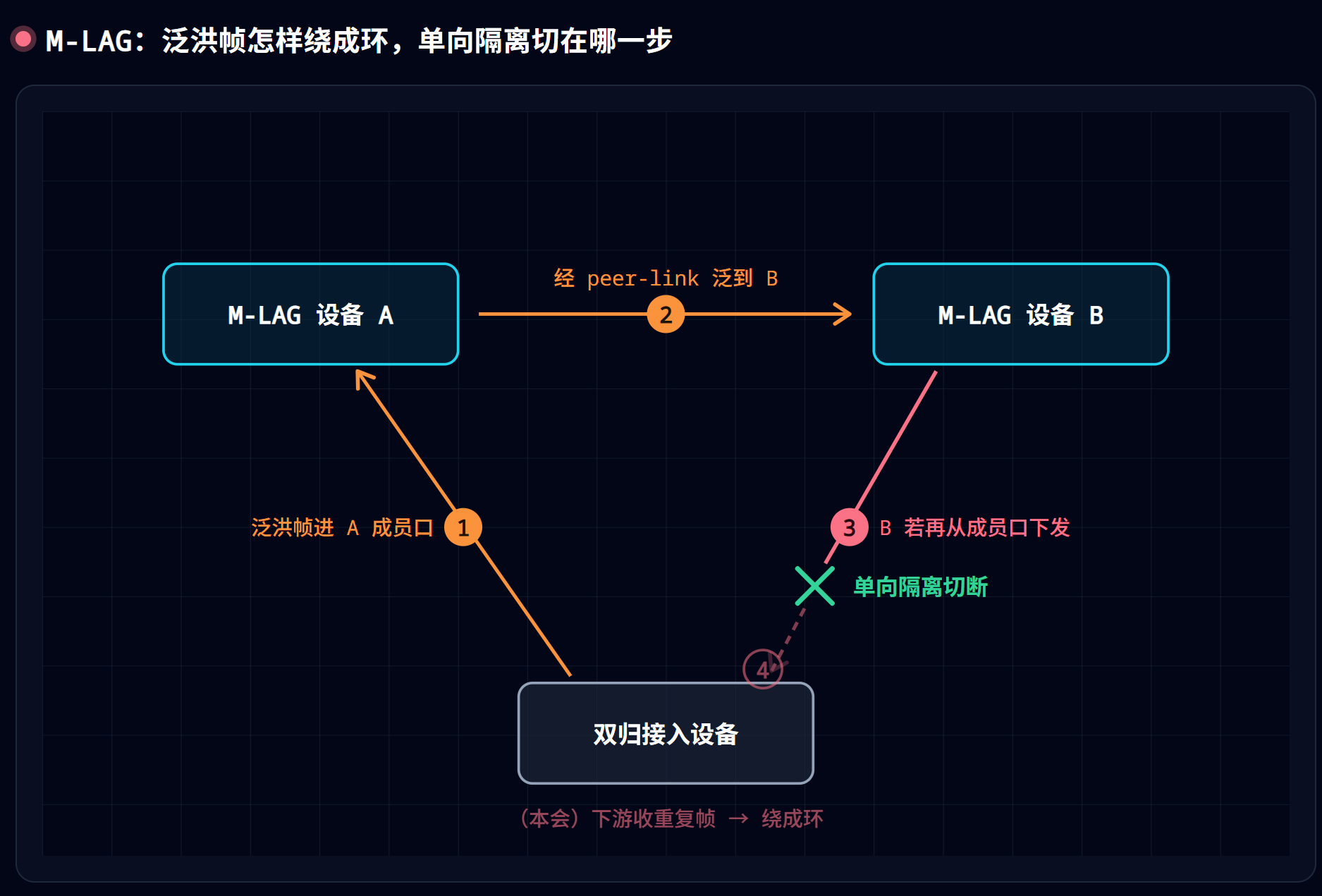
M-LAG 不靠 STP block 端口来破这个环,而是用单向隔离——华为的实现方式是在成员口上自动下发一组 ACL:
- 放行 源为 peer-link、目的为 M-LAG 成员口 的三层已知单播报文;
- 拒绝 源为 peer-link、目的为 M-LAG 成员口 的其余所有报文。
效果就是:从 peer-link 进来的泛洪帧,不准再从本端的成员口”漏”给下游。 几何上掐断了那条闭合路径——这和”STP 破环”里”逻辑上消灭闭合路径”是同一招棋,只是 M-LAG 换了一种实现方式。
这是 MLAG 类技术的通用原理,不是华为的小聪明:
- 华为叫单向隔离;
- 思科叫 vPC loop avoidance rule——明文规定”从 peer-link 进来的流量不允许从任何 vPC 成员口转发出去”,硬件上靠 egress_vsl_drop 标志位实现;
- H3C DRNI 走 IEEE 802.1AX 的 DRCP 分布式中继规则,本质相同。
两个边界要记住:
- 生效范围:对二层流量(单播/组播/广播)和三层组播生效,三层已知单播不受限(所以上面 ACL 要专门放行它)。
- 生效前提:只在下游双归接入时才下发隔离;如果下游是单归接入,不下发。而且当本端成员口 down 时,会通过 peer-link 通知对端撤销对应隔离规则——因为这时正需要 peer-link 帮忙把流量转到对端去补位。
为什么唯独放行三层单播?
一句话:一方面必须放,一方面放了也无所谓。
必须放——否则路由黑洞。 M-LAG 是双活网关,主机的三层流量 hash 到哪台都可能,而目的的下一跳有时只能从另一台出去。这时收到包的设备必须把路由后的流量经 peer-link 交给对端、由对端从成员口送出去。要是把三层单播也一刀拦了,这部分流量就被丢进黑洞——这跟”三层逃生链路”是同一个道理。
放了也无所谓——它根本掀不起风暴。 单向隔离要防的是”会复制扩散”的泛洪流量(广播 / 组播 / 未知单播):一份进来复制成 N 份乱跑,加上二层帧没有 TTL,才会无限循环成风暴。而三层单播是查表后点到点的一份,不复制就不会重复;更何况它带着 TTL,万一真绕了也会自己归零而死。既不泛洪、又有 TTL 兜底,放行它根本不构成环路风险。
总结:三厂商术语对照
到这里,M-LAG 的接口角色就全了。前面反复说”三家原理一致、叫法不同”,这里一次性对齐——拿着思科或 H3C 设备的同学,照着这张表平移即可:
| 角色 / 概念 | 华为 M-LAG | 思科 vPC | H3C DRNI |
|---|---|---|---|
| 技术统称 | M-LAG | vPC | DRNI |
| 同步 + 二层转发主链路 | peer-link | vPC peer-link | IPL(端口叫 IPP) |
| 双主检测 / 心跳链路 | 双主检测 DAD | peer-keepalive link | Keepalive 链路 |
| 配对协商协议 | DFS Group | CFS(Cisco Fabric Services) | DRCP(IEEE 802.1AX) |
| 对下游的聚合成员口 | M-LAG 成员口 | vPC member port | DR 接口 |
| 链路聚合接口本身 | Eth-Trunk | EtherChannel / Port-Channel | 聚合接口 |
| 保护性下线 | error-down | errdisable | 接口抑制下线 |
| 防环机制 | 单向隔离 | vPC loop avoidance rule | 同源分布式中继规则 |
三、流量模型:正常怎么走,故障怎么扛
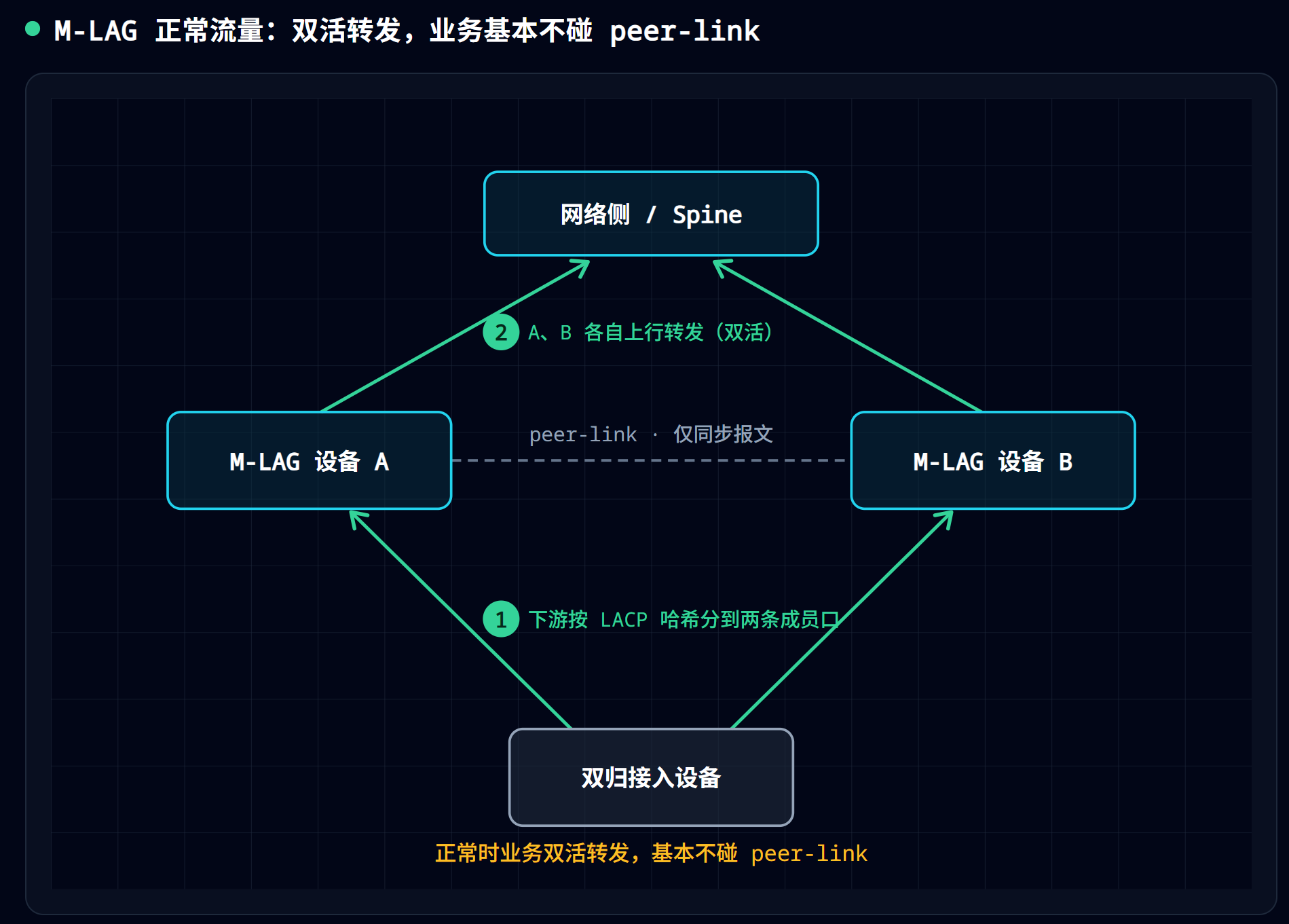
正常情况:业务流量基本不碰 peer-link
按”什么类型的流量”做个穷尽切分:
- 南北向单播(下游 ⇄ 网络侧):下游靠 LACP 哈希把流量分摊到两条成员链路上,两台设备共同转发;上行再按各自路由表发出去。双活。
- 东西向二层单播(同子网,下游之间):本地优先转发,直接从本设备成员口出,不绕 peer-link。
- 东西向三层(跨子网):双活网关——两台都是网关、共用相同虚拟 MAC,本地查路由直接转,也不绕 peer-link。
- 广播 / 组播 / 未知单播(BUM):会泛洪,但有单向隔离兜着——从 peer-link 过来的那一份不会再从成员口泛给下游,下游不收重复帧,也不成环。
本地优先转发 = 流量到了哪台 M-LAG 设备,就优先从这台设备”自己的”成员口直接送给下游,而不是把流量推过 peer-link 让对端去转。
这个”优先用本地物理成员、别走设备间互联”的思想,在堆叠里也有,叫”Eth-Trunk 本地优先转发”(跨框流量优先从本框的成员口出,别走堆叠线)。M-LAG 的”本地优先”和它是同一套思路,只是把”堆叠线”换成了”peer-link”。
由此得到一个重要认知:
正常情况下,业务流量基本不走 peer-link。peer-link 跑的主要是同步报文。它不是流量主干道,而是”同步主干道 + 故障备用道”。
为什么是基本不走 peer-link?但仍有少数正常业务会合法地经过 peer-link,主要两种:
- 下游单归挂在对端:目的设备只接在 B 上(单归),流量到了 A 就得借 peer-link 送到 B;
- BUM 泛洪:广播/组播/未知单播本来就会在 A、B 之间经 peer-link 泛洪扩散(只是被单向隔离限制了”再往成员口下发”)。
故障情况:M-LAG 的看家本领
按”哪个部件坏了”做穷尽切分,四个场景:
场景一:上行链路故障(主设备朝网络侧的口坏了)
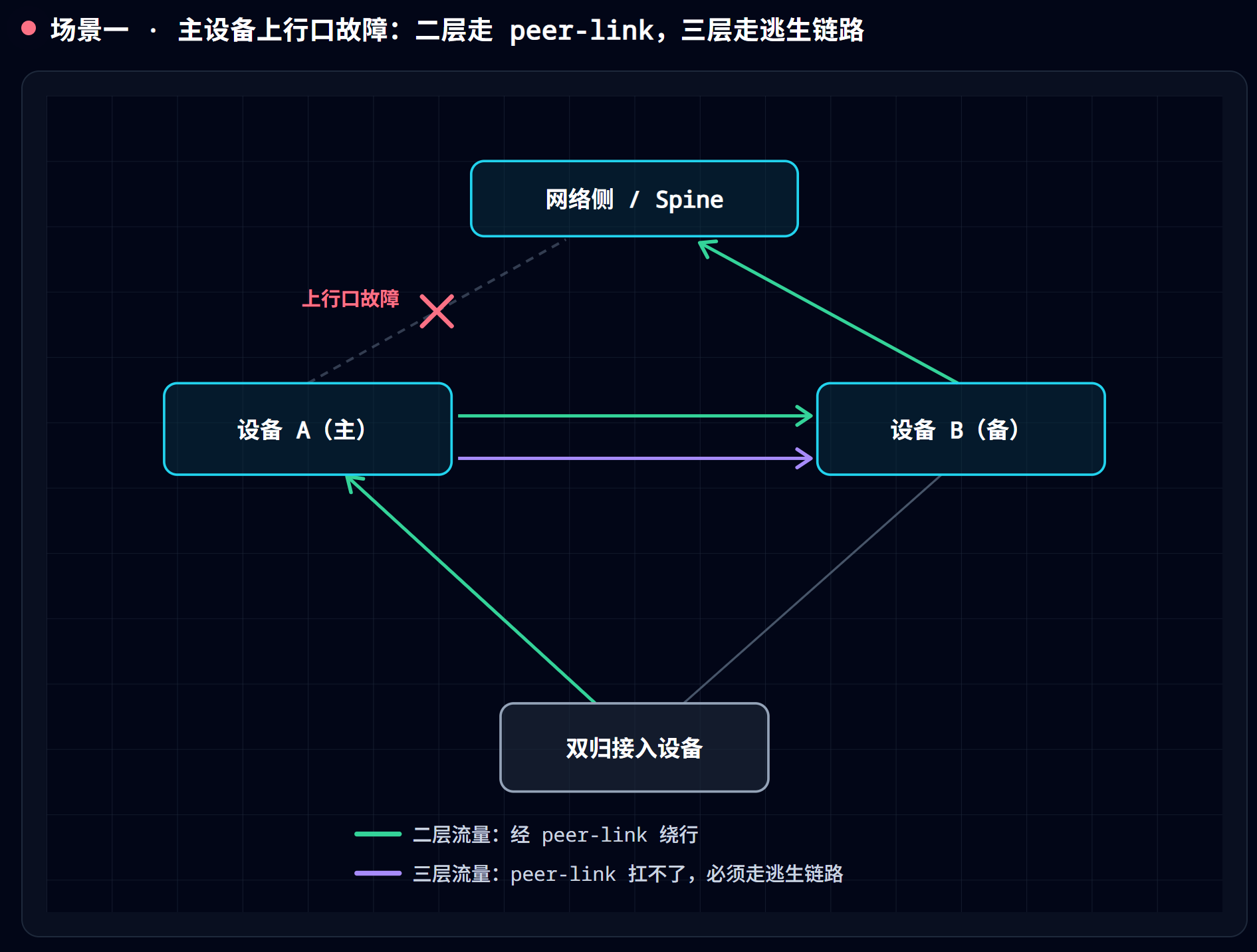
这里二层和三层的处理截然不同,是最容易栽跟头的地方——也是前面埋的伏笔兑现的地方。
- 二层接入:主设备上行口坏了,它把流量从 peer-link 转给备设备,备设备从自己的上行口发出去。纯二层桥接,而 peer-link 本来就是条二层链路,天生支持——“走 peer-link”成立。
- 三层接入:到达主设备的上行流量是要被路由出去的,而 peer-link 是二层链路,默认不在两台设备之间承载三层路由邻居/路由。主设备自己的出口路由失效后,它没有一条”经备设备出去”的路由,流量直接被路由黑洞丢掉。
所以结论是硬性的:
三层接入场景,必须单独配一条三层逃生链路(三层互联 + 路由协议或静态路由),让主设备在上行口故障时学到一条”下一跳 = 备设备(经逃生链路)”的路由,把三层流量绕到备设备再路由出去。
工程上还有一条建议:别把三层中转路由硬叠在 peer-link 的 VLANIF 上。 peer-link 是 M-LAG 专用链路、带防环转发限制;职责上应当让 peer-link 管二层同步、逃生链路管三层绕行,两者互不干扰。
一句话忠告:记住”peer-link 是二层、扛不了三层路由”这一条,你就理解了为什么三层场景必须有逃生链路。
(另外注意一个二次故障的坑:别让上行/逃生链路和 DAD 心跳走同一条路。否则 peer-link 再断时 DAD 也跟着没了,又回到”共命运”的老问题——这正是前面强调 DAD 必须物理独立的原因。)
场景二:下行成员口故障(连下游的成员口坏了)
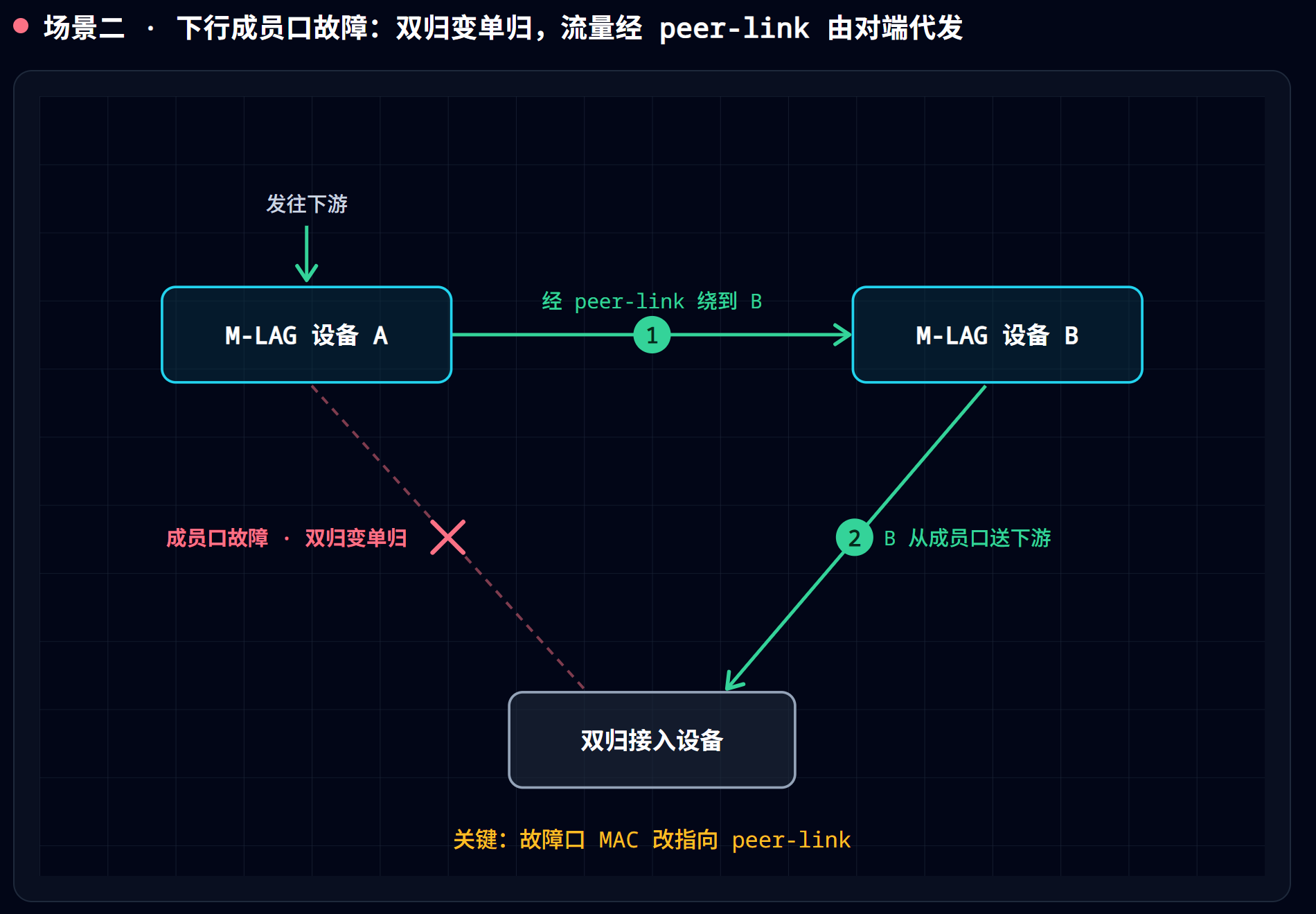
- 故障成员口所在链路 down,双归退化为单归。
- DFS 主备状态不变;但如果坏的恰好是”主成员口”,对端的备成员口会由备升主,流量切到那条链路转发。故障成员口的 MAC 指向 peer-link(让发往它的流量经 peer-link 绕到对端出去)。
- 故障恢复后不回切(no preemption):升主的继续当主,原主恢复后甘当备。
为什么不回切? 第一次切换躲不掉,回切却是”额外、无收益”的切换:主备角色一变就要重跑协商、伴随瞬断,切回去不带来任何功能好处、还可能在端口反复 up/down 时引发反复横跳,所以干脆不切(即 HA 系统常见的非抢占策略)。但这只是”角色标签不翻回去”——成员口一恢复,MAC 表项会重新指回本地口,流量照走本地、不再绕 peer-link。
- 组播补充:成员口故障时不再按组播地址奇偶做负载分担,全部由端口 Up 的那台转发。
组播是一对多复制,没法像单播那样用 LACP 随意散列,于是 M-LAG 用了个静态取巧法——按组地址奇偶分工:一半组归主设备转、一半归备设备转,两台各算各的,把组播大致均分成两半,实现双活分担。一旦某台成员口故障、失去本地出口,再分担就得绕 peer-link 还成倍复制,于是放弃奇偶,全部组播交给仍 Up 的那台统一转发。
场景三:主设备整机故障
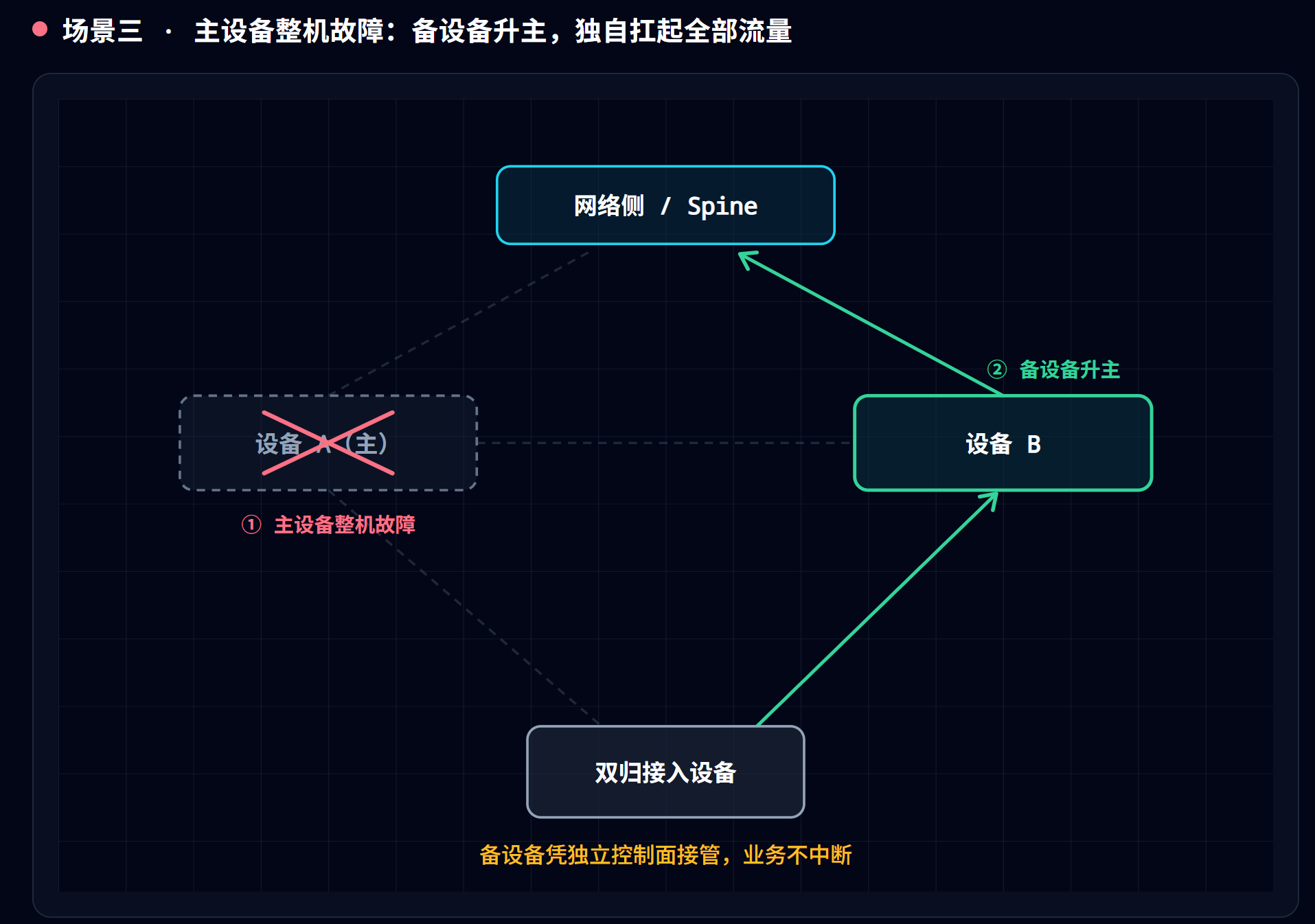
- 备设备升主,它下游侧的成员口仍 Up、转发状态不变、继续转发;主设备侧链路变 Down,双归退化单归。业务不中断。
- 恢复顺序:peer-link 先 Up → DFS 重新协商 → 成员口恢复 Up → 流量恢复负载分担。原主恢复后仍是主,原备恢复后仍是备。
为什么是这个顺序? 因为一台刚恢复的设备,表项是空的或过时的,直接放它转发业务会黑洞、会成环。所以必须”先同步好、再上岗”:① peer-link 先 Up——它是同步命脉,不通则一切免谈;② DFS 重新协商,把 B 积累的全部表项灌给 A,让它的脑子追上现状;③ 成员口最后才放开——只有表项确认同步完成,才允许它承接业务(华为”error-down 后默认等 240s 再恢复”,留的正是这段同步时间)。
- (备设备故障是对称的:主备状态不变,备设备侧链路 Down、主设备照常转发。)
场景四:peer-link 故障 —— 最凶险,直奔脑裂
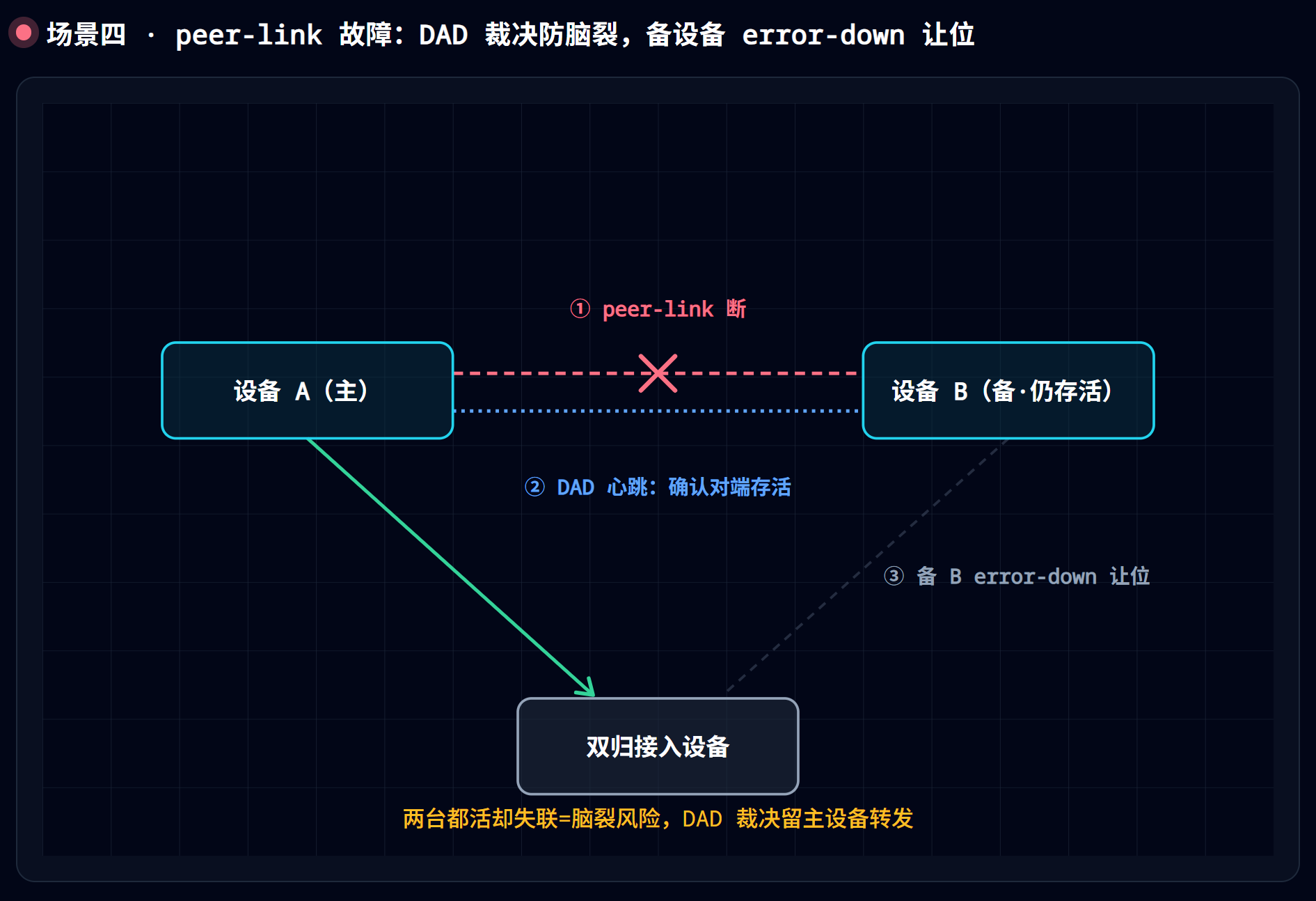
peer-link 断了、但两台设备都还活着——这是最危险的局面。如果不处理,两台都会用相同的身份(同 MAC、同 IP)对外说话,网络立刻乱套:MAC 漂移、表项混乱。这就是脑裂。
处理逻辑,正是前面那套”裁决”机制登场的时刻:
- DAD 确认对端还活着 → 既然 peer-link 断了又都活着,就必须让一台退场,只留一台对外转发。
- 默认行为(普通以太 / VXLAN / IP 双归):peer-link 故障但 DAD 心跳正常时,备设备上除逻辑口、管理口、peer-link 口和堆叠口以外的接口被置为保护性下线(即 error-down)——备设备主动让位,只剩主设备转发。
Error-Down 的是业务口(成员口 + 上行口等对外转发的口);保留的是管理口、peer-link、逻辑口、堆叠口这几条”救援与恢复的命脉”。关掉嘴巴别说话,但留着耳朵和血管别断气——这就是这句话的全部含义。
- 谁退场不一定看 DFS 主备,有更细的裁决顺序(华为缺省逻辑):
- 先比 M-LAG 上行端口状态(需配
uplink-port enable):本机上行口没全坏、或对端上行口全坏的一方胜出;没胜出的一方接口下线。 - 上行状态一致时,再比带宽:取 peer-link 故障前 10~20s 的历史带宽,与触发 DAD 时的实时带宽相减,带宽差值大的一方接口下线。
恢复:peer-link 恢复后,处于 error-down 的 M-LAG 接口默认 240s 后自动恢复 Up(给表项同步留足时间),其它接口立即恢复。
二次故障兜底:这正是 HB DFS(通过心跳链路协商出的主备)的用武之地——当原 DFS 主或备故障恢复、但 peer-link 仍没好时,触发 HB DFS 为备的一方相应端口下线,避免双主下的流量异常。
几个工程优化(落地时常配):
- 在相连接口配
port-status fast-detect enable,让芯片快速感知物理状态变化,提升正切收敛; - 用
m-lag unpaired-port suspend/reserved灵活控制某个口在此场景是否被下线——比如 DAD 心跳口要设成reserved,绝不能被关掉。
延伸思考:上行口故障时,最下游的服务器如何感知网络侧链路断了?
答:它不感知,也不需要感知。 坏的是 M-LAG 设备朝上(网络侧)的口,服务器朝下连的那两条成员链路物理上都还好好的——服务器的 LACP 看到两条腿都 Up,照旧往两条腿哈希发流量,完全无感。落到”上行口已坏的那台”的流量,由 M-LAG 内部自己消化:
- 流量哈希到上行口正常的那台 → 直接从自己上行口送出去;
- 流量哈希到上行口已坏的 A → A 知道自己上行没路了,把流量绕给对端 B、从 B 的上行口送出去。
关键的不对称点(也是本场景真正的考点):A”把流量绕给 B”走哪条路,二层和三层不一样——
- 二层流量:直接经 peer-link 桥接给 B(peer-link 本就是二层链路,天生支持);
- 三层流量:peer-link 扛不了路由,必须额外配一条三层逃生链路,A 才能学到”下一跳 = B”的路由,把三层流量绕过去再路由出去。
| 角色 | 感知什么 | 怎么处理 |
|---|---|---|
| 服务器 | 什么都不感知 | 两条成员链路都 Up,照旧往两条腿哈希 |
| 设备 A(上行口故障本端) | 自己的上行口 down | 绕给 B:二层走 peer-link,三层走逃生链路 |
| 网络侧 Spine | 只看到 A 那条上行邻居 down | 自己路由收敛,与 M-LAG 内部无关 |
一句话:下行口坏,上游 Spine 无感,靠 A 本端 + 服务器 LACP 内部消化;上行口坏,下游服务器无感,靠 A 本端把流量绕给 B——但二层走 peer-link、三层必须走逃生链路,这是上行故障比下行故障多出来的那道坎。
延伸思考:成员口故障时,最上游的 Spine 如何感知服务器侧链路断了?
答:它不感知,也不需要感知。 这恰恰是 M-LAG”对外演成一台”的精髓——内部成员口的增减对上游完全透明。真正”感知并处理”故障的是另外两个角色:
- 服务器自己:靠 LACP 检测到去 A 的成员链路 down,主动把上行流量全压到去 B 的那条链路。这是服务器的行为,不关 M-LAG 设备的事。
- 故障口本端的设备 A:A 第一时间知道自己的成员口 down 了(本地端口状态),于是把该服务器 MAC 的转发表项改指向 peer-link。这样即便上游把下行流量仍丢给 A,A 也能经 peer-link 甩给 B、由 B 送下去。
而最上游的 Spine 全程无感:在它眼里 A、B 始终是一台逻辑设备、一组等价下一跳,它照旧按哈希把流量丢过来,路由表和转发行为完全不用动。
| 角色 | 感知什么 | 怎么处理 |
|---|---|---|
| 服务器 | 去 A 的链路 down | LACP 自动把上行流量切到 B |
| 设备 A(故障口本端) | 自己的成员口 down | 本地端口状态,MAC 表项改指 peer-link |
| 上游 Spine | 什么都不感知 | 继续当它俩是一台,按等价下一跳转发 |
一句话:M-LAG 把故障的影响死死摁在内部消化,对上游保持”还是那一台、啥也没变”的假象——这正是它的价值所在。也正因为上游无感、可能把下行流量仍丢给”成员口已坏的 A”,peer-link 才必须随时准备扛这条绕行流量(呼应前面”peer-link 为什么要高带宽”)。
收尾:所有故障都在回答同一个问题
你回看这四个场景会发现,它们本质上都在回答同一句话——**”对外那张统一的脸还在不在?会不会冒出两张脸同时说话?”**
- peer-link 在 → 两台同步着一起演;
- peer-link 断了 → DAD 裁决留一台继续演,另一台保护性下线退场。
这就是 M-LAG 的全部精髓:
对外一台,对内两台;同步靠 peer-link,裁决靠 DAD。 所有接口、所有故障处理,都是这句话的展开。
下一篇预告:理解了心智模型,我们就落到地面——M-LAG 到底怎么配(DFS Group、peer-link、成员口、DAD 一步步配置),之后再讲怎么维护、怎么排障。