3 个减法算尽 CIDR:掩码、步长、主机数一次出
一、开局一张图
二、这套算法解决什么
每天和子网打交道的人都遇到过这个场景:手上一个 /26,要立刻说出它的十进制掩码、能塞多少台主机、相邻子网之间差多少。或者反过来,看到 255.255.192.0 要立刻说出对应的 CIDR。
二进制写下来一位一位数 1 是最笨的办法。这套算法只做几个减法,就能把 CIDR、十进制掩码、子网步长、可用主机数 四个量一起算出来。全程不需要除法,也不需要查任何表。
三、先理清概念
IPv4 地址是个 32 位的二进制数,按 8 位一段分成 4 个十进制段,每段叫一个 octet(中文有时候就直接叫”字节”或”第几段”)。比如 192.168.1.10 写成二进制是:
1 | 11000000.10101000.00000001.00001010 |
一个 IP 地址里,前一截是 网络位(network bits),后一截是 主机位(host bits)。
前者标识”这是哪个子网”,后者标识”在这个子网里是哪台主机”。
CIDR 这个写法 /N 就是告诉你”前 N 位是网络位”。
剩下的就是主机位:主机位数 = 32 − N。这是整套算法唯一需要的关键变量。
子网掩码(subnet mask)和 CIDR 表达的是同一件事,写法不同:把网络位全写成 1、主机位全写成 0,再按 8 位一段转成十进制。/26 对应:
1 | 11111111.11111111.11111111.11000000 |
运维干活时常常要在 CIDR、十进制掩码、地址块大小、主机数之间反复跳,不掌握个速算法每次都打开计算器太烦。
四、为什么 “256 减块大小” 能算出掩码值
理解了这一步,整个算法才站得住。
看 /26 的最后一个字节:
1 | 11000000 = 192 ← 子网掩码该字节的值 |
8 位里有 2 位是 1(网络位),6 位是 0(主机位)。
一个保留 6 位主机位的字节能表达 2^6 = 64 种取值——这个字节空间里有 64 个连续 IP 属于同一个子网。
这个 64 就叫 块大小(block size),相邻子网的网络号正好差这么多,所以它也叫 步长。
字节的总取值范围 0~255,共 256 种。块大小占了 64,剩下的 256 − 64 = 192 正好就是掩码值:
1 | 11000000 = 128 + 64 = 192 ← 掩码值(网络位贡献的十进制和) |
掩码值 + 块大小 = 256,永远成立。整套算法就是这个等式的反复套用。
五、超过一个字节怎么办
/26 主机位只有 6 位,全在最后一个字节里折腾,直接套 “256 − 块大小” 就完事。
但 /18 主机位有 14 位,跨过了字节边界,掩码长成这样:
1 | 11111111.11111111.11000000.00000000 |
直接写 块 = 2^14 = 16384 没用,因为 16384 已经超出了 256,没法直接 “256 − “ 它。
一种做法是先除 256(16384 ÷ 256 = 64),再 256 − 64 = 192。除法能算对,但心算时思路要从”减”切换到”除”,容易卡。
更顺手的办法:超过 8 就反复减 8,每减一次掩码字节往左跳一位。从头到尾都是减法,不用切思路。
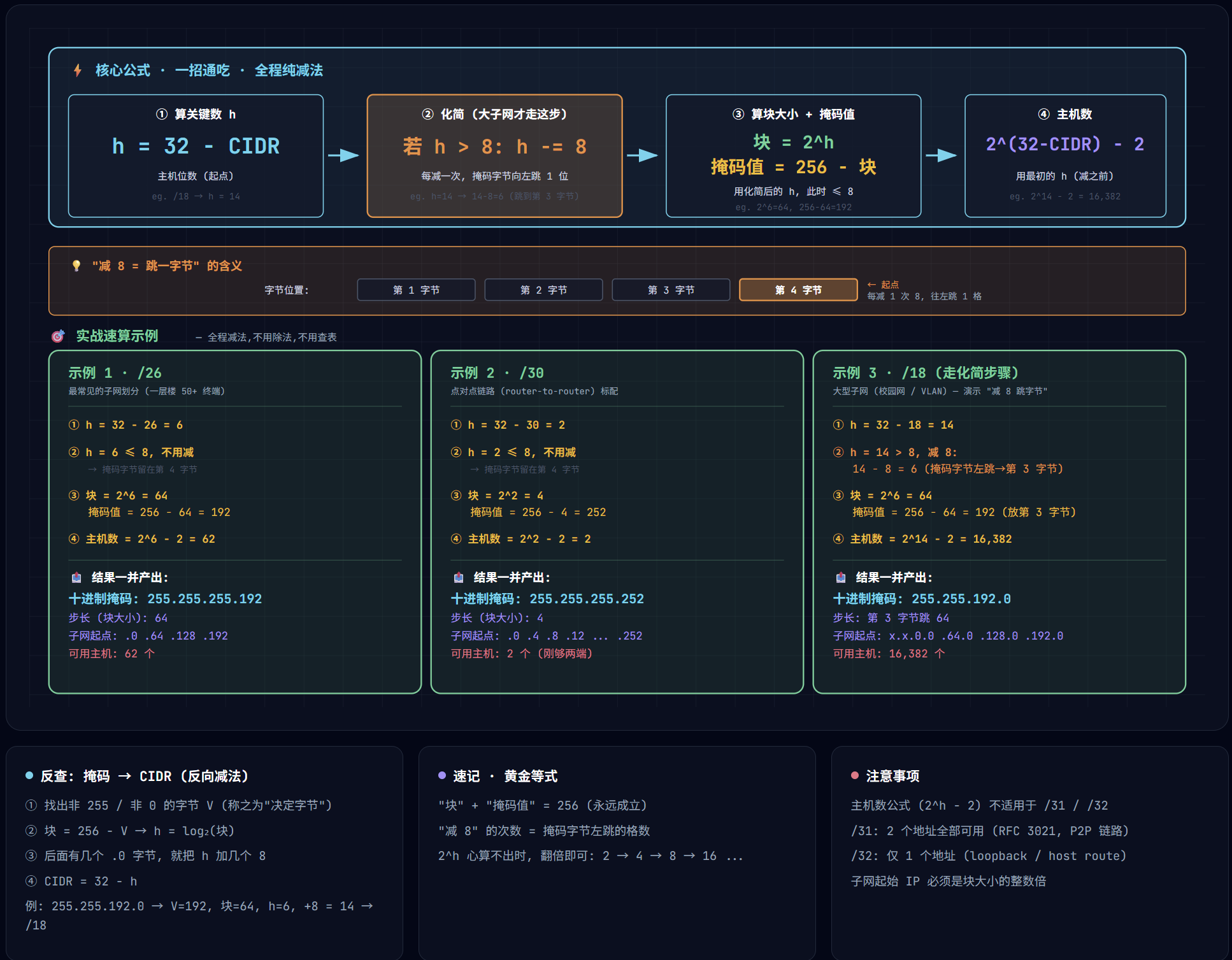
六、算法本身:四步流程
把 CIDR 写作 /N。
第 1 步 · 算关键数 h
1 | h = 32 − N |
h 就是主机位的总数,后面所有计算都从这里出发。
第 2 步 · 化简(只在 h > 8 时走)
如果 h ≤ 8:直接跳过这一步,掩码值会落在第 4 字节。
如果 h > 8:反复执行 h = h − 8,直到 h ≤ 8。每减一次 8,掩码字节就往左跳一位:
| 减 8 的次数 | 掩码字节落在哪 | 适用 CIDR 范围 |
|---|---|---|
| 0 | 第 4 字节 | /25 ~ /32 |
| 1 | 第 3 字节 | /17 ~ /24 |
| 2 | 第 2 字节 | /9 ~ /16 |
| 3 | 第 1 字节 | /1 ~ /8 |
跳过的字节填 0,更左边的字节填 255。
要记得把化简之前的原始 h 留着,第 4 步算主机数还要用。
第 3 步 · 算块大小和掩码值
1 | 块大小 = 2^h ← 用化简后的 h |
掩码值填到第 2 步里”跳到”的那个字节。块大小同时就是子网步长——相邻子网在那个字节上差这么多。
第 4 步 · 算可用主机数
1 | 可用主机数 = 2^h(原) − 2 |
h(原) 是化简之前算出的那个 h(也就是 32 − N)。减掉的 2 是网络号和广播地址,正常子网都要扣。
/31 和 /32 是例外:/31 按 RFC 3021 用于点对点链路,2 个地址全部可用;/32 只有 1 个地址,常用于 loopback 或 host route。
七、三个典型案例
例 1 · /26(不化简)
1 | 第 1 步: h = 32 − 26 = 6 |
子网掩码 255.255.255.192,步长 64,子网起点 .0 / .64 / .128 / .192,每个子网容纳 62 台主机。/26 是企业内网划分最常见的尺寸。
例 2 · /30(不化简,点对点链路标配)
1 | 第 1 步: h = 32 − 30 = 2 |
子网掩码 255.255.255.252,可用主机 2 个,正好够路由器两端各 1 个 IP。两台设备直连互联场景里 /30 是传统配置。
例 3 · /18(化简一次)
1 | 第 1 步: h = 32 − 18 = 14 |
子网掩码 255.255.192.0,第 3 字节每跳 64 是一个子网,子网起点 x.x.0.0 / .64.0 / .128.0 / .192.0,每个子网容纳 16,382 台主机。校园网、数据中心 VLAN 经常用这种规模。
八、反向:从十进制掩码倒推 CIDR
逆向操作还是减法,一样的思路:
- 找出十进制掩码里非 255、非 0 的那个字节,记作 V
- 块大小 = 256 − V
- 该字节内的主机位数 =
log₂(块大小) - 加上后面所有 .0 字节贡献的位数(每个 .0 字节算 8 位主机)
- CIDR = 32 − 总主机位数
举个例:255.255.192.0
- V = 192(第 3 字节)
- 块大小 = 256 − 192 = 64
- 第 3 字节内的主机位 = log₂(64) = 6
- 后面 1 个 .0 字节贡献 8 位
- 总主机位 = 6 + 8 = 14
- CIDR = 32 − 14 = /18
碰到掩码全是 255 或全是 0 的边界情况:255.255.255.255 是 /32,0.0.0.0 是 /0,特殊但好记。
九、几条要记的事
黄金等式:块大小 + 掩码值 = 256。整套算法就是它的反复应用。
两组要背熟的数:
- 2 的幂:2, 4, 8, 16, 32, 64, 128, 256。心算不出就翻倍数过去。
- 256 减 2 的幂得到的掩码序列:128, 192, 224, 240, 248, 252, 254, 255。无论掩码值落在哪个字节,可能的取值就这 8 个,背熟了一眼就能反查。
子网起始 IP 必须是块大小的整数倍。/26 块 = 64,子网起点只能在 .0、.64、.128、.192,不能从 .30 开始划。这是 IP 寻址硬性的对齐要求,不是约定俗成。
特殊掩码长度清单:
/31:2 个地址全部可用(RFC 3021,专门给点对点链路)/32:仅 1 个地址(loopback、host route、ACL 单条规则等)/0:匹配所有地址(默认路由0.0.0.0/0用的就是它)
十、常见错误清单
下面这些是教学和实操里反复看到的坑。前两个是这套算法独有的,后面是通用子网计算容易出错的地方。
1. 主机数算成了”化简后 h”的次方
这是本算法最容易踩的坑,专门坑走了化简步骤的大子网。
错的算法:
1 | /18: h = 14 → 减 8 → h = 6 |
正确:
1 | /18: h(原) = 14, 化简后 h = 6 |
第 2 步的化简只是为了让掩码值能塞进单个字节,不改变主机位的实际数量。算主机时一定要回到化简之前的那个 h。
2. 跳过的字节忘记填 0
/18 化简后掩码值 192 落在第 3 字节,第 4 字节是被”跳过”的字节,必须填 0:
1 | 正确: 255.255.192.0 |
记忆方法:减 8 几次,就有几个字节要填 0,全在掩码值的右边。
3. 把块大小当掩码值
“/26 的掩码是 64” — 这是把块大小说成掩码值了。两个数字虽然相关,但用途完全不同:
- 块大小(64):相邻子网网络号的差,子网规划用
- 掩码值(192):实际写到子网掩码里那个字节的数
黄金等式 两者相加 = 256,记牢就不会混。
4. 忘记减 2
算出 /26 块 = 64,直接说能装 64 台主机。漏掉了网络号(首 IP)和广播地址(末 IP)这两个不能分配给终端的地址。可用主机其实是 62。
-2 是 IP 协议层面的硬性规则,常规子网都要扣。
5. /31 和 /32 直接套公式
机械套公式会得出荒谬的数字:
| CIDR | 套公式结果 | 实际正确值 |
|---|---|---|
| /31 | 2 − 2 = 0 ❌ | 2(RFC 3021 特例,全部可用) |
| /32 | 1 − 2 = −1 ❌ | 1(loopback、host route) |
碰到 /31、/32 直接记结论,不套公式。
6. /24 看着像出错
/24 走完算法是 掩码值 = 256 − 256 = 0,写出来就是 255.255.255.0。那个 0 看着像哪里搞错了,其实是对的——它表示”第 4 字节整个是主机位”。
同理 /16 → 255.255.0.0、/8 → 255.0.0.0。边界字节是 0 是常态,不是 bug。
7. 子网起点不对齐
想把 192.168.1.30/26 当成一个子网,配置一推就出错。/26 块大小 64,子网起点必须是 64 的整数倍:
1 | 合法起点: .0, .64, .128, .192 |
.30 这个地址落在 .0~.63 这个块的中间,它本身只是子网内的一个主机地址,不是子网网络号。规划子网时第一步就检查起点对不对齐。
8. CIDR 数字方向搞反
下意识觉得 /24 比 /16 “大”——数字大听着应该规模也大。其实正好反过来:
| CIDR | 主机位 | 子网容量 |
|---|---|---|
| /16 | 16 | 65,534 |
| /24 | 8 | 254 |
| /30 | 2 | 2 |
CIDR 数字是网络位数,网络位越多,留给主机的越少,子网越小。
十一、算法流程速记
整个流程压成一行就是:
1 | h = 32 − N → (h > 8 时反复 −8, 每次跳一字节) → 块 = 2^h, 掩码 = 256 − 块 → 主机 = 2^h(原) − 2 |
熟练之后,看到任何 CIDR 都能在十秒内说出全部四个量。