决胜信创存储:基于鲲鹏920与openEuler离线部署Ceph集群
1 前言必读
1.1 计算机发展历程
计算机存储系统的发展,遵循着从“内”向“外”,从“集中”到“分布”的路径
早期计算机的磁盘直接挂在总线上,只为单一主机服务。其特点是结构简单,但容量和性能受单机限制,形成“数据孤岛”
为解决数据共享与集中管理,出现了通过网络提供文件级服务(NAS)和块级服务(SAN)的专用存储设备
但本质上仍是纵向扩展(Scale-Up) 的集中式架构,其核心瓶颈在于:性能、容量受限于单个控制器或设备
当互联网时代到来,数据量呈指数级爆发(大数据),业务要求永不停机(高可用)
分布式存储应运而生,其核心思想是:将数据分散存储到大量廉价的通用服务器上,并通过软件来协同这些存储资源,形成一个统一可靠的存储池
分布式存储通过“软件定义”和“Scale-Out”哲学,将数量庞大的普通硬件组织成强大且具有弹性的存储系统,是应对数据洪流时代的必然选择
1.2 Ceph介绍
目前主流的分布式存储系统选择不少,其中 Ceph、MinIO、HDFS 和 GlusterFS 这四款尤为突出
表1 主流分布式存储软件比对
| 特性 | Ceph | MinIO | HDFS | GlusterFS |
|---|---|---|---|---|
| 核心存储类型 | 块、对象、文件 | 对象存储 | 文件存储 | 文件存储 |
| 架构特点 | 无中心架构,模块化设计 | 轻量级,云原生友好 | Master-Slave | 无元数据服务器 |
| 核心优势 | 强一致性,扩展性强,统一存储 | S3兼容,部署简单,K8s友好 | 高吞吐顺序读写,容错性强 | 部署管理简单,扩展性强 |
| 典型应用场景 | 私有云/虚拟化存储池 | 用户上传文件、备份归档 | 大数据分析、日志处理 | 科研数据共享、媒体资源库 |
| 潜在局限 | 配置和维护相对复杂 | 目前只有对象存储功能 | 不适合低延迟访问和大量小文件存储 | 小文件性能表现可能不佳 |
特点非常明显的就是Ceph,Ceph 是一个开源分布式存储系统
其核心设计目标就是构建一个可水平扩展、无单点故障的分布式存储系统
1.3 Ceph创新点
Ceph的三个关键创新——CRUSH算法、RADOS和统一存储架构
这三者共同构成了Ceph的基石,使其在分布式存储领域独树一帜
1.3.1 CRUSH算法
在传统分布式存储中,通常需要一个中心化的“元数据服务器”来记录每个文件具体存储在哪个硬盘、哪台服务器上。当数据量巨大时,这个元数据服务器本身就会成为性能瓶颈和单点故障
为此Ceph设计了CRUSH算法
CRUSH(Controlled Replication Under Scalable Hashing,中文可翻译为可扩展哈希下的受控复制)是一种数据分布算法,而非一个查询目录。它不是一个存储在某个服务器上的“表”,而是所有Ceph客户端和节点都知晓并可以执行的一套计算规则
当客户端要存储一个对象(例如,一个图片文件)时,Ceph会对这个对象执行一个哈希函数,得到一个唯一的PG ID,然后,CRUSH算法将这个 PG ID 作为输入,再结合当前集群的实时拓扑图(包含了哪些机架、哪些服务器、哪些硬盘,以及它们的权重),通过一个确定的、伪随机的计算过程,直接输出一个结果:这个对象应该被存储在“硬盘A”、“硬盘B”和“硬盘C”上
关于客户端的解释
这个“客户端”是能够理解Ceph协议、并拥有CRUSH算法计算能力的软件组件。它不是最终用户的操作系统本身,而是操作系统内的一个专用驱动或服务
最终用户的操作系统并不直接“访问Ceph集群”,它只是看到了一个本地的块设备(如
/dev/rbd0)在块存储场景中,最常见的客户端就是
librbd库 和 Linux内核中的krbd驱动KVM/QEMU 虚拟化环境:
librbd就是这个“智能客户端”物理服务器或容器环境:
krbd内核模块就是这个“智能客户端”
1.3.2 RADOS存储层
RADOS(Reliable Autonomic Distributed Object Store)是Ceph存储系统的核心,一个真正意义上的分布式对象存储层。我们通常所说的“Ceph集群”,其本质就是一个RADOS集群
一个RADOS集群由MON和OSD守护进程组成
一个硬盘对应一个OSD进程,OSD不仅负责存储数据对象,还负责处理数据复制、恢复、回填和一致性检查
MON进程负责维护集群成员状态、身份认证信息和集群拓扑图(Cluster Map) 的主副本。MON不直接处理数据读写,它的工作是保证集群元数据的一致性。通常由少量(如3或5个)MON节点组成一个基于Paxos协议的小集群,以实现高可用
1.3.3 统一存储架构:一套系统,三种服务
文件存储、块存储和对象存储正是计算机领域最核心和最常见的三种存储类型
文件存储:解决“人类可读”的共享问题:文件存储的组织结构——目录(文件夹)和文件——是对我们现实世界中信息管理方式的直接数字化映射
块存储:解决“机器需要”的性能问题:它提供最底层的磁盘空间,由操作系统来格式化为文件系统(如ext4, NTFS)。因为它绕过了文件系统的开销,直接对磁盘块进行读写,所以性能最高、延迟最低。
对象存储:解决“互联网规模”的数据问题:对象存储通过扁平化的结构和唯一的对象ID,打破了目录层级的限制,实现了近乎无限的横向扩展
传统方案需要部署和管理多套不同的存储系统,成本高且运维复杂,Ceph在稳固的RADOS基础之上,通过添加不同的接口层,用一套存储集群同时提供块、对象和文件三种存储服务
表2 Ceph接口和存储类型对应关系
| Ceph接口 | 存储类型 |
|---|---|
| RBD(RADOS Block Device) | 块存储,将一个分布式对象集合虚拟成一个连续的、固定大小的块设备 |
| RGW(RADOS Gateway) | 对象存储,提供了一个与Amazon S3和OpenStack Swift兼容的RESTful API网关 |
| CephFS(Ceph File System) | 文件存储,提供了一个符合POSIX标准的分布式文件系统 |
1.3.4 总结
当客户端需要读写数据时,它首先从MON获取最新的Cluster Map
客户端使用这份Cluster Map和CRUSH算法,独立计算出目标数据存储在哪些OSD上
客户端直接与这些OSD进行通信,完成数据的读写操作
Ceph集群:可以看成一个庞大的自动化无人仓库系统
MON:可以看成仓库的中央调度室,只保管最新的仓库地图(Cluster Map)
OSD:可以看成每一个智能机器人货架,负责存储具体的货物(数据对象)
CRUSH算法:一套精确的货物定位导航算法
1.4 Ceph节点类型和功能
节点指的是一台参与Ceph集群的物理服务器或虚拟机
守护进程是Ceph集群中真正提供功能的软件服务。每个守护进程都是一个独立的、长时间运行的后台进程
表3 Ceph节点类型和功能
| 节点/守护进程类型 | 官方简称 | 核心职责描述 |
|---|---|---|
| Monitor (监视器) | MON | 维护整个集群状态的关键映射 (Cluster Map),包括Monitor映射、OSD映射、归置组(PG)映射和CRUSH映射等,负责集群的身份验证服务 |
| Manager (管理器) | MGR | 负责收集和暴露集群的运行时指标与当前状态(如存储利用率、性能指标和系统负载),为Ceph Dashboard和REST API提供支持 |
| Object Storage Device (对象存储设备) | OSD | 这是集群中实际存储数据的守护进程。每个OSD守护进程通常对应一块物理硬盘。它们负责处理数据复制、恢复、再平衡,并通过心跳机制向Monitor报告部分监控信息 |
| Metadata Server (元数据服务器) | MDS | 仅为Ceph文件系统 (CephFS) 存储元数据,以此减轻存储集群的负载,并提供高效的元数据操作(如ls, find等命令)。对象存储和块存储不需要MDS。 |
| RADOS Gateway (对象存储网关) | RGW / RadosGW | 提供与Amazon S3和OpenStack Swift兼容的RESTful API网关,是Ceph对象存储服务的入口。 |
节点是物理服务器或虚拟机,为守护进程提供运行环境
守护进程是在节点上运行、提供具体功能的软件服务
角色是节点或守护进程在集群中的逻辑身份,由其运行的守护进程类型决定
一个节点可运行多种守护进程,从而具备多重角色,共同协作提供统一存储服务
这种清晰的职责分离,使得Ceph集群能够灵活部署
用户既可以采用融合架构,将多种守护进程混合部署在少量节点上以节省资源
也可以采用分离架构,将MON、MGR、RGW等关键服务部署在专用节点上,以实现更高的性能和稳定性,满足大规模生产环境的需求
2 部署前的几个关键说明
2.1 安装环境说明
1、硬件环境
本次实验环境采用三台鲲鹏920芯片【ARM架构】的服务器,内存为128G,具备4个万兆光口
2、软件环境
操作系统采用openEuler-20.03-LTS
openEuler 的软件仓库中支持两个 Ceph版本
- 在openEuler-20.03-LTS 系列中的 Ceph是 12.2.8 Luminous版本
- 在openEuler-22.03-LTS 系列中的 Ceph 16.2.7 Pacific版本
本实验环境采用openEuler-22.03 Sp4镜像自带的Ceph版本是16.2.7 Pacific版本
操作系统的下载地址为:https://repo.openeuler.org/openEuler-{release}/everything/{arch}/Packages/
【请注意根据实际情况自身调整括号中的内容】
本实验环境CPU是鲲鹏920,采用ARM架构,因此选择对应架构的操作系统包文件,openEuler-22.03-LTS-SP4-everything-aarch64-dvd.iso
注意下载使用
everything版本,避免再单独做ceph的软件仓库
各个节点的角色定义、主机名、网络地址规划等信息如下:
表4 Ceph部署步骤相关信息
| cehp节点 | 角色 | 主机名 | 公网地址 | 私有(集群)地址 |
|---|---|---|---|---|
| 节点1 | MON、MGR、OSD | cephnode1 | 192.168.10.131 | 10.10.0.1 |
| 节点2 | MON、MGR、OSD | cephnode2 | 192.168.10.132 | 10.10.0.2 |
| 节点3 | MON、OSD | cephnode3 | 192.168.10.133 | 10.10.0.3 |
2.2 安装要点
1、集群命名
集群名称应为不含空格的字符串,默认名称为 ceph,也支持根据实际规划指定其他名称
2、集群唯一标识
每个 Ceph 集群均通过一个全局唯一的 UUID 进行识别。该标识符在早期主要用于 Ceph 文件系统(CephFS)中标识文件系统 ID,现作为集群级别的身份凭证。
3、节点主机名规划
所有节点的主机名应提前规划并保持一致命名规则,确保任意节点间均可通过主机名互相访问,避免依赖 IP 地址
4、网络规划
建议为集群配置两个逻辑或物理网络:
- 公共网络:用于客户端与集群之间的通信
- 集群网络:承载 OSD 间数据同步等后台流量
5、软件仓库准备
在离线部署场景下,需提前搭建并测试本地软件仓库,确保所有节点均可正常访问并安装所需的 Ceph 软件包
6、关于权限【重点】
网上很多教程都没有针对数据目录的权限进行重点阐述,使得按照各种教程上的命令,执行到最后一步服务启动的时候会报错
ceph集群的各种守护进程,例如MON、MGR往往都是以ceph身份运行,因此ceph用户必须具备对应的数据目录和文件可读可写的权限
掌握了这个核心要点,命令其实就很好理解,例如我们可以以root身份执行ceph-mon命令,然后利用chown命令去将数据目录的权限修正
1 | mkdir -p /var/lib/ceph/mon/ceph-cephnode1 |
又或者可以直接使用sudo -u ceph命令以ceph身份去执行ceph-mon命令
1 | mkdir -p /var/lib/ceph/mon/ceph-cephnode1 |
7、关于节点之间的时钟同步
Ceph 对节点间的时间同步有极其严格的要求,默认允许的最大时钟偏差(clock skew)只有 0.05 秒(50毫秒)
建议使用chronyd 服务进行ceph集群内的时间同步
具体配置可参考我的另外一篇文章
2.3 节点的推荐数量
Ceph Mon节点使用 Paxos 算法的一种变体来维持整个集群中关于map和其他关键信息的共识
Paxos晦涩难懂,这里就不细说了
由于 Paxos 的特性,只有当大多数监控器都是active 时,Ceph 才能维持法定人数(即建立共识)
对于多节点 Ceph 群集的小型或非关键部署,建议部署三个Mon节点
对于规模较大的集群或打算承受双重故障的集群,建议部署五个Mon节点
只有在极少数情况下,才有选择部署七个或更多Mon节点
奇数个节点的原因:使用奇数个节点(3, 5, 7…)可以在保持相同容错能力的前提下,最大化资源利用率。例如,3节点和4节点都只能容忍1台故障,但3节点更节省资源
当三个节点中一个节点出现问题后,集群仍然可以运行
1 | ceph -s |
当cephnode1离线后,从上面结果可以看出,ceph集群的剩余两个节点让然满足法人人数的要求值,并且MGR节点的原来备份节点成功成为了主节点,MGR服务依旧正常
3 部署前环境准备
3.1 关键步骤说明
1、在各节点上按照《表4 Ceph部署步骤相关信息》将IP地址配置完毕
2、主机名与解析:确保三个节点的主机名设置正确,并且可以通过 /etc/hosts 或DNS相互解析
3、SSH互信:配置 cephnode1 到 cephnode2 和 cephnode3 的SSH免密登录,这不本身并不是必选项,只不过免密登录方便批量分发文件
4、规划守护进程:
- **Monitor (MON)**: 在三个节点上各部署一个,以实现高可用
- **Manager (MGR)**: 为实现高可用至少在两个节点上部署,与MON协同工作
- **Object Storage Device (OSD)**: 每个节点上根据硬盘数量部署,进程数量与硬盘数量1:1对应,但是部署操作是一次性完成
3.2 具体步骤说明
1、在各节点上配置修改主机名
在节点1上配置
1 | hostnamectl set-hostname cephnode1 |
在节点2上配置
1 | hostnamectl set-hostname cephnode2 |
在节点3上配置
1 | hostnamectl set-hostname cephnode3 |
设置完成后,您可以注销当前用户重新登录,然后通过以下hostnamectl status --static命令验证新的主机名是否已经生效
2、在各节点配置主机名解析
1 | cat >> /etc/hosts << EOF |
操作前提:三个节点的操作系统已完成安装,主机名已成功设置
3、禁用SELinux
编辑/etc/selinux/config,将相关内容修改如下:
1 | SELINUX=disabled |
4、配置 cephnode1 到 cephnode2 和 cephnode3 的SSH免密登录,方便分发文件【可选】
这个步骤可选,主要是为了方便将cpeh的配置文件、秘钥文件等快速分发
SSH秘钥的批量分发,我们这里使用sshpass和ssh-copy-id将公钥拷贝到目标主机上
具体步骤是:先生成秘钥,然后使用sshpass工具提供密码,再通过ssh-copy-id命令将本地公钥拷贝到目标主机的~/.ssh/authorized_keys文件中
1 | ssh-keygen -t rsa -f ~/.ssh/id_rsa -N "" |
参数解析:
-f ~/.ssh/id_rsa:指定生成的私钥文件路径和文件名。请根据需要修改此路径。
-N "":这是实现免交互的关键
5、配置防火墙
下表总结了 Ceph 各个组件需要使用的关键端口:
| 组件 | 端口/范围 | 协议 | 用途说明 |
|---|---|---|---|
| Ceph Monitor | 6789 |
TCP | 用于 Ceph 客户端和守护进程连接到 Ceph 监控守护进程,msgr1协议 |
| Ceph OSD | 6800-7300 |
TCP | OSD 守护进程通信范围。每个 OSD 至少需要4个端口 |
| Ceph Monitor | 3300 |
TCP | 客户端和守护进程连接 Monitor 的msgr2协议,优先级高 |
我们可以在已部署的ceph集群上进行验证
例如MON服务进程
1 | ss -tunlp | grep mon |
在开发或测试环境中,有些人会选择直接关闭防火墙来快速解决问题
但是在生成环境下,防火墙不建议关闭
针对Ceph集群所需要端口进行配置,打开响应端口
1 | firewall-cmd --add-port=6789/tcp --permanent |
关于端口:
- msgr2协议默认使用3300端口
- 传统的msgr1协议则使用6789端口
- 默认情况下,Ceph守护进程会同时绑定到v1和v2协议的端口(
ms_bind_msgr1和ms_bind_msgr2都默认为true),这确保了新旧客户端的兼容性
至此,Ceph集群部署前准备工作完成
3.3 集群的身份认证与密钥管理命令
部署环节中经常会使用到集群的秘钥管理命令,先说结论:集群初始化使用ceph-authtool操作本地数据库,后续均使用ceph auth 操作集群数据库
ceph auth 和 ceph-authtool 都可以被归类到 Ceph 集群的”身份认证与密钥管理”命令中,它们共同构成了 Ceph 安全模型(基于共享秘密密钥的认证)的两大支柱
更精确地说:
- **
ceph-authtool**:属于 “低级”、”本地” 的密钥环管理工具。它不直接与集群通信,而是在文件层面操作密钥环,是构建集群信任的”基石工具” - **
ceph auth**:属于 “高级”、”集群” 的身份认证管理工具。它通过连接到已运行的 Monitor 来管理集群中央的认证数据库,是日常运维的”管理工具”
3.3.1 ceph-authtool
ceph-authtool 是 Ceph 集群中一个用于本地管理认证密钥和密钥环文件的低级工具。它不直接与集群交互,而是在本地文件系统上操作密钥文件
常用参数:
| 参数 | 缩写 | 说明 |
|---|---|---|
--create-keyring |
-C |
创建一个新的密钥环文件。如果文件已存在,则会报错。 |
--gen-key |
-g |
为指定的实体生成一个新的秘密密钥。 |
--name |
-n |
指定要操作的实体名称(如 client.admin, mon., osd.0)。 |
--add-key |
-a |
从一个文件或标准输入导入一个已存在的密钥到密钥环。 |
--cap |
为实体设置能力。格式为:`–cap <mon | |
--list |
-l |
列出密钥环中的所有密钥及其能力。 |
--print-key |
-p |
仅打印指定实体的密钥,不输出其他信息。适用于脚本。 |
--import-keyring |
从另一个密钥环文件中导入所有密钥。 |
因为是本地管理,集群部署后,ceph-authtool 使用几率很少
在初始化ceph集群使用的就是--create-keyring、--gen-key、--cap以及--import-keyring四个参数
3.3.2 ceph auth
ceph auth 是用于与正在运行的 Ceph 集群交互,管理其内部认证数据库(Auth Database)的核心命令。所有操作都是实时且全局的,会立即影响整个集群
| 分类 | 命令格式 | 功能描述 | 常用选项 | 示例 | 适用场景 |
|---|---|---|---|---|---|
| 信息查询 | ceph auth ls |
列出集群中所有认证实体(用户/守护进程) | -o <file> (输出到文件) |
ceph auth ls -o auth_list.txt |
审计、查看所有用户 |
ceph auth get <entity> |
获取指定实体的完整认证信息(含密钥) | 无 | ceph auth get client.admin |
查看特定用户详情 | |
ceph auth print-key <entity> |
仅打印指定实体的密钥 | 无 | ceph auth print-key client.myapp |
脚本中获取密钥 | |
| 用户创建 | ceph auth add <entity> |
创建新用户(自动生成密钥) | --cap <svc> <caps> |
ceph auth add client.myapp mon 'allow r' osd 'allow rwx pool=mydata' |
创建新用户,不立即需要密钥文件 |
ceph auth get-or-create <entity> |
创建并获取用户密钥环(常用) | --cap <svc> <caps>, -o <file> |
ceph auth get-or-create client.myapp mon 'allow r' osd 'allow rwx pool=mydata' -o /etc/ceph/ceph.client.myapp.keyring |
一键创建用户并导出密钥文件【最常用】 | |
ceph auth get-or-create-key <entity> |
创建用户并仅返回密钥 | --cap <svc> <caps> |
ceph auth get-or-create-key client.myapp mon 'allow r' osd 'allow rwx' |
仅需密钥字符串的场景(如 libvirt 配置) | |
| 密钥管理 | ceph auth import -i <keyring> |
从密钥环文件导入用户到集群 | 无 | ceph auth import -i /tmp/backup.keyring |
用户迁移、批量恢复、集群引导 |
| 权限管理 | ceph auth caps <entity> <new-caps> |
覆盖式更新用户能力 | 无 | ceph auth caps client.myapp mon 'allow r' osd 'allow rwx pool=pool1, allow r pool=pool2' |
修改用户权限(会完全替换旧权限) |
ceph auth rm <entity> ceph auth del <entity> |
从集群删除用户 |
``ceph auth get-or-create
3.3.3 对比总结
| 特性 | ceph-authtool |
ceph auth |
|---|---|---|
| 操作对象 | 本地密钥环文件 | 运行中集群的认证数据库 |
| 集群状态 | 无需集群运行 | 必须要有运行的 Monitor |
| 主要用途 | 1. 集群初始引导 2. 密钥备份/恢复 3. 手动构造密钥文件 | 1. 日常用户管理 2. 动态权限调整 3. 从集群获取密钥文件 |
| 权限模型 | 本地文件权限 | 基于 client.admin 等用户的集群级权限 |
| 关系 | 制造”钥匙”的工厂 | 管理”钥匙”注册和分发的”公安局” |
简单来说:在集群搭建好之后,几乎所有的日常认证管理工作都应使用 ceph auth
ceph-authtool 则更多地用于集群的”从零到一”的启动过程,或者在一些离线、恢复的特殊场景下使用
4 集群初始化
正式进入离线部署环节
1、使用ssh登录到第一个节点
本环境下,首个ceph节点的主机名称是cephnode1,这个主机名称务必不要弄错
1 | ssh cephnode1 |
2、在该节点上安装ceph
1 | yum install -y ceph |
验证:
1 | ceph -v |
安装完成后,系统会自动生成/etc/ceph目录以及ceph用户【因此不需要单独新建ceph用户】
注意:安装的前序步骤是要完成本地部署本地的软件仓库部署
3、通过uuidgen创建生成UUID(通用唯一标识符)
UUID通过算法组合(如时间戳+MAC地址+随机数)确保全球唯一性
1 | uuidgen |
记录下生成的UUID,届时会将这个UUID号保存到集群配置文件
4、创建一个空的/etc/ceph/ceph.conf文件即可,否则ceph-mon初始化节点命令时报错,提示找不到文件
也可以直接创建准备好的的配置文件
1 | cat > /etc/ceph/ceph.conf <<EOF |
这里的
ceph.conf的文件名称是根据集群的名称决定,默认的集群名称就是ceph,这个名称可以手工指定
配置文件的参数解释:
集群标识: 使用 UUID
e5074a24...唯一标识公共网络 (
192.168.10.0/24): 承载客户端流量。三个 Monitor 的 IP 也位于此网络,方便客户端发现集群集群网络 (
10.10.0.0/24): 承载 OSD 间数据同步等后台流量。这通常要求三个节点之间还有另一套物理网卡连接到这个独立的子网Ceph集群默认启用CephX认证,确认启用
另外注意,配置文件中如非必要,不需要针对osd_pool_default_pg_num、osd_pool_default_min_size参数做制定,后续再创建RadosGW时候容易报错
5、在部署 Ceph 集群的初始阶段,为 Monitor 守护进程创建一个高权限的“启动钥匙”,以便它们能够相互认证并建立集群
这个生成的 /tmp/ceph.mon.keyring 文件是构建集群信任体系的第一步
为了更好理解第五步至第十步操作,详见下图帮助理解
注意:如果系统提示ceph-authtool 没有找到,需要安装ceph包
1 | ceph-authtool --create-keyring /tmp/ceph.mon.keyring --gen-key -n mon. --cap mon 'allow *' |
验证:此时/tmp/ceph.mon.keyring的内容如下:
1 | [mon.] |
6、生成管理员密钥,生成client.admin用户并将该用户添加到密钥中
1 | ceph-authtool --create-keyring /etc/ceph/ceph.client.admin.keyring --gen-key -n client.admin --cap mon 'allow *' --cap osd 'allow *' --cap mds 'allow *' --cap mgr 'allow *' |
验证:此时/etc/ceph/ceph.client.admin.keyring内容如下:
1 | [client.admin] |
7、创建一个名为 client.bootstrap-osd 的专用客户端用户,并为其生成密钥和精确的权限,然后将这些信息保存在一个密钥环文件/var/lib/ceph/bootstrap-osd/ceph.keyring中,该文件用于在集群中引导(创建和注册)新的 OSD 守护进程
1 | ceph-authtool --create-keyring /var/lib/ceph/bootstrap-osd/ceph.keyring --gen-key -n client.bootstrap-osd --cap mon 'profile bootstrap-osd' --cap mgr 'allow r' |
验证:此时/var/lib/ceph/bootstrap-osd/ceph.keyring内容如下:
1 | [client.bootstrap-osd] |
8、将前两步生成的密钥添加到ceph.mon.keyring
将两个关键用户的密钥合并到一个名为 /tmp/ceph.mon.keyring 的密钥环文件中,为后续初始化 Ceph Monitor 做准备
1 | ceph-authtool /tmp/ceph.mon.keyring --import-keyring /etc/ceph/ceph.client.admin.keyring |
验证:此时/tmp/ceph.mon.keyring的内容如下,应有三个字段内容:
1 | [mon.] |
9、【可选】为/tmp/ceph.mon.keyring密钥改变所属者和所属组
1 | chown ceph:ceph /tmp/ceph.mon.keyring |
这里调整文件的所属者和所属组目的是为了后续第12步操作
因为第12步骤是使用sudo -u ceph命令利用ceph身份进行操作,如果不调整文件的所属者和所属组则会报错
如果第12步骤采用root账户也可以略过此步骤
10、使用主机名、主机 IP 地址和 FSID 生成monitor映射,并将其保存为 /tmp/monmap
这个步骤是创建和操作 Ceph Monitor 映射(monmap)
Monitor 映射是 Ceph 集群最关键的基础映射之一,它记录了:
- 集群 FSID
- 所有 Monitor 节点的名称
- 所有 Monitor 节点的 IP 地址和端口
- 当前 epoch(版本号)
注意命令里的参数细节,不要输入错误
1 | monmaptool --create --add cephnode1 192.168.10.131 --add cephnode2 192.168.10.132 --add cephnode3 192.168.10.133 --fsid e5074a24-1b7e-4780-a05c-308f2a19c79e /tmp/monmap |
这里的主机名、主机 IP 地址和 FSID需要根据实际情况填写
--add参数一共添加了三个节点的主机名和实际IP地址,这个IP是public networ,即三个MON节点的通讯网络
验证:可以通过monmaptool --print命令带参数查看
1 | monmaptool --print /tmp/monmap |
11、【关键步骤】在节点1上创建Monitor数据目录,并更改所属者和所属组
数据目录的名称规则是/var/lib/ceph/mon/{集群名称}-{主机名称}
例如本环境下,集群名称默认是ceph,主机名称是cephnode1
因此Monitor数据目录就是/var/lib/ceph/mon/ceph-cephnode1
1 | mkdir -p /var/lib/ceph/mon/ceph-cephnode1 |
特别注意:
MON进程的数据目录的的权限必须是ceph用户和ceph组可读,否则Mon服务无法启动
验证相关权限,确保权限正确
1 | ll -d /var/lib/ceph/mon/ceph-cephnode1 |
12、初始化cephnode1节点的MON进程
在下面命令/etc/ceph/ceph.conf`文件即可,否则下面命令汇报错
1 | sudo -u ceph ceph-mon --mkfs -i cephnode1 --monmap /tmp/monmap --keyring /tmp/ceph.mon.keyring |
这条命令是 Ceph 集群部署中初始化第一个 Monitor 守护进程数据目录的核心步骤,非常关键
这条命令是 Ceph 集群从无到有的转折点。它通过组合预先准备好的认证材料(keyring)和拓扑信息(monmap),创建出了第一个能够独立运行、具备形成集群能力的 Monitor 实例
在此命令成功执行并启动服务之前,Ceph 集群实际上是不存在的
注意:
cephnode1是集群节点名,/tmp/monmap为前序步骤生成的monitor映射文件,/tmp/ceph.mon.keyring为前序步骤生成的密钥- 这个
ceph-mon命令会在/var/lib/ceph/mon/ceph-cephnode1生成相关配置文件
验证:使用tree命令查看
1 | tree /var/lib/ceph/mon/ |
MON进程所使用目录结构中文件的作用
核心就是**store.db 就是 Ceph 集群的”大脑记忆库”,而 keyring 是它的”身份证”**
Monitor 使用一个键值数据库,这个数据库就是 store.db 目录下的所有文件共同构成的
keyring:这是本 Monitor 守护进程自身的密钥环文件。它包含了mon.cephnode1的密钥,用于在集群中认证自身- **
kv_backend**:一个文本文件,里面通常只写着一行字,如rocksdb,用来指明使用哪种键值数据库作为存储后端 store.db/目录下的文件:CURRENT:指向当前使用的清单文件。MANIFEST-*:数据库的清单,记录了所有 SST 文件及其层级。*.log:预写日志(Write-Ahead Log)文件,用于保证数据一致性。LOCK:数据库锁文件,确保同一时间只有一个进程访问数据库。OPTIONS-*:数据库的配置选项。
13、【可选但是非常关键】核心步骤
确保服务正常启动的一个核心要素,就要是要确保数据
即需要确保数据目录和密钥文件的权限正确,以便 ceph 用户能够访问
1 | chown -R ceph:ceph /var/lib/ceph/mon/ceph-cephnode1 |
14、启动并启用cephnode1节点上的MON进程
注意启用的服务格式是:ceph-mon@{节点名}
1 | systemctl enable ceph-mon@cephnode1 --now |
注意:这里启动的时候,systemctl使用了服务模板复用的能力
在/usr/lib/systemd/system/ceph-mon@.service的脚本中,利用了%i 作为占位符传入的参数(@ 后面的部分)
1 | ExecStart=/usr/bin/ceph-mon -f --cluster ${CLUSTER} --id %i --setuser ceph --setgroup ceph |
可以看出服务的本质就是利用ceph-mon传参数进行启动
15、验证
查看服务是否正确
1 | systemctl status ceph-mon@cephnode1 |
注意,此时如果输入ceph -s命令,命令会卡主
“卡住”的状态的原因是:
此时只启动了 cephnode1 节点的MON守护进程,而由于法定人数要求规定,3个 Monitor 需要至少 2个在线才能形成法定人数(n/2 + 1 = 2)
ceph -s 会尝试连接所有配置中指定的 Monitor,由于 cephnode2 和 cephnode3 不可达,客户端会等待直到超时,在超时之前,命令看起来就是”卡住”的状态
新手在初始化MON节点时候,可以逐步建立 Monitor 集群,而不是一次性配置所有节点
这样既能获得必要的集群状态信息,又避免了无限等待的问题
16、完整的全部命令,可以在诸如cephnode1初始化节点上一次性输入【注意根据实际情况调整一些IP地址、主机名等参数】
1 | cat > /etc/ceph/ceph.conf <<EOF |
5 添加其他Mon节点
对于多节点 Ceph 群集的小型或非关键部署,建议部署三个Mon节点
对于规模较大的集群或打算承受双重故障的集群,建建议部署五个Mon节点
只有在极少数情况下,才有理由部署七个或更多Mon节点
本教程环境采用三MON节点
1、【关键】在集群的剩余节点上首先安装ceph软件包
1 | yum -y install ceph |
2、登录到已经初始化MON节点的cephnode1上
将/tmp/ceph.mon.keyring 和/tmp/monmap文件拷贝至需要部署的cephnode2和cephnode3的/tmp目录下
将配置文件/etc/ceph/ceph.conf以及密钥文件/etc/ceph/ceph.client.admin.keyring拷贝至需要部署的cephnode2和cephnode3的相应目录下
如果密钥文件不拷贝,其他节点将无法访问集群
1 | scp /tmp/ceph.mon.keyring /tmp/monmap root@cephnode2:/tmp |
从上面可以看出来,如果配置 cephnode1 到 cephnode2 和 cephnode3 的SSH免密登录,执行的效率会提高不少,否则每次都要输入密码
注意
由于scp命令不会在目标主机上创建目录
因此如果没有在节点上安装ceph软件包,不会创建
/etc/ceph目录,会导致ceph的密钥文件和配置文件分发失败
4、【关键步骤】分别在cephnode2和cephnode3两个节点创建Monitor数据目录
对于cephnode2节点执行以下命令
1 | mkdir -p /var/lib/ceph/mon/ceph-cephnode2 |
对于cephnode3节点执行以下命令
1 | mkdir -p /var/lib/ceph/mon/ceph-cephnode3 |
再次提醒Monitor数据目录的的权限必须是ceph用户和ceph组可读可写,否则MON服务无法启动
5、分别在cephnode2和cephnode3两个节点执行ceph-mon命令
对于cephnode2节点执行以下命令
1 | chown ceph:ceph /tmp/ceph.mon.keyring |
对于cephnode3节点执行以下命令
1 | chown ceph:ceph /tmp/ceph.mon.keyring |
6、在节点上启动ceph-mon服务
对于cephnode2节点执行以下命令
1 | systemctl enable ceph-mon@cephnode2 --now |
对于cephnode3节点执行以下命令
1 | systemctl enable ceph-mon@cephnode3 --now |
7、验证:在任何节点上执行ceph -s
1 | cluster: |
其中返回结果中显示mon: 3 daemons, quorum cephnode1,cephnode2,cephnode3 (age 27s),表示三个MON节点之间通讯正常
8、【可选】启用msgr2协议
1 | ceph mon enable-msgr2 |
6 添加MGR节点
Ceph Manager (MGR) 的主要功能是收集集群指标和提供外部接口(如Dashboard)
为了保证集群管理功能的持续性,建议部署主备两个节点
工作机制:集群中同时只有一个MGR处于活动(active) 状态,其余的都处于备用(standby) 状态。当活动的MGR出现故障时,备用的MGR会自动接管工作
MGR通常与MON节点部署在同一台主机上(非强制)
6.1 部署步骤
1、在cephnode1节点上部署MGR服务
1 | sudo -u ceph mkdir /var/lib/ceph/mgr/ceph-cephnode1 |
集群完毕后,后续就要用ceph auth命令操作运行中集群的认证数据库,创建 MGR(Manager)守护进程的认证密钥环
2、在cephnode2节点上部署MGR服务
1 | mkdir /var/lib/ceph/mgr/ceph-cephnode2 |
可以看到我在cephnode2上的操作和在cephnode1上的操作,有点区别
其实就想告诉大家,MON、MGR进程容易失败的操作点,就是在进程所对应的数据目录的权限上
MON、MGR进程都是以ceph用户运行,因此必须具备对数据目录的读写权限
3、验证
通过简单的 ceph -s命令,可以看到cephnode1为主节点,cephnode2为备节点
1 | ceph -s |
至此,ceph集群的MGR节点的服务部署完毕
6.2 MGR主备切换
针对ceph集群中的MGR节点,会存在主备切换的需求
例如活动MGR节点所在的主机需要进行硬件更换、固件升级或操作系统重启
在重启主机前,手动将MGR角色切换到另一个备用节点。这样,管理功能(如Dashboard、API)在维护期间几乎不会中断,维护完成后再将节点加回集群
操作步骤是
1、利用ceph -s查看当前MGR主(活动)节点,例如cephnode1
2、使用故障转移命令ceph mgr fail cephnode1,这里的cephnode1为活动节点,此方法最为直接
集群会将cephnode1标记为故障节点,并迅速提升备用MGR为新的活动实例
注意:
1、在执行切换前,请确认至少有一个备用MGR处于 standby 状态且健康。如果所有MGR都不健康,切换可能导致管理功能暂时不可用
2、MGR负责的是管理功能,不存储用户数据。因此,切换MGR不会影响集群的IO路径(数据读写),只会短暂影响通过MGR提供的服务,如Dashboard访问或部分ceph命令的响应
7 部署MGR Dashboard【可选】
首先默认情况下,在安装ceph软件包时候,ceph-mgr-dashboard是被一起安装的
验证
1 | rpm -q ceph-mgr-dashboard |
说明模块已经被安装在目标节点上
默认情况下没有能提供网络服务的模块在运行,验证如下:
1 | ceph mgr services |
7.1 部署步骤
1、使用 ceph mgr module enable dashboard 启用
2、【核心步骤】Dashboard默认使用SSL,不制作证书会导致服务无法启动,此步骤在当前版本下无法忽略
1 | ceph dashboard create-self-signed-cert |
如果以上证书方法都遇到问题,可暂时使用一下命令关闭SSL进行测试:ceph config set mgr mgr/dashboard/ssl false
关闭SSL后,Dashboard将使用HTTP协议在默认8080端口提供服务
3、【可选,但生成环境下非常推荐】改变监听地址和端口
一般而已,像绝大数网上教程说的一样,可以直接绑定到某一个ceph节点
1 | ceph config set mgr mgr/dashboard/server_addr 192.168.10.131 |
但是由于MGR是主备两个节点,如果绑定一个IP地址,无法实现高可用,因此特别建议采用以下这种方式
将dashboard的地址针对MGR主备节点进行分别绑定
1 | ceph config set mgr mgr/dashboard/mgr.cephnode1/server_addr 192.168.10.131 |
如果关闭了SSL,则设置非SSL地址和端口命令如下:
1 | ceph config set mgr mgr/dashboard/mgr.cephnode1/server_addr 192.168.10.131 |
注意根据实际情况替换实例中的端口号
特别注意,如果要调整修改端口和地址,需要对ceph的config进行删除
我们先通过ceph config get mgr查看当前配置
1 | ceph config get mgr |
然后再用ceph config rm mgr删除对应的键值对
例如下述操作
1 | ceph config rm mgr mgr/dashboard/mgr.cephnode1/server_addr |
4、【关键步骤】创建访问的管理员账号
创建一个包含密码的文件
1 | cat > password.txt << EOF |
然后创建dashboard的访问用户,权限为administrator
1 | ceph dashboard ac-user-create admin -i password.txt administrator |
注意:出于安全考虑的最佳实践
ceph dashboard ac-user-create命令很可能必须通过-i选项指定一个包含密码的文件,而不能在命令行中直接明文输入密码
5、重启服务
注意,mgr-dashboard并没有像网上教程那样可以利用systemctl去启用服务
只能通过关闭和启用mgr module去实现
1 | ceph mgr module disable dashboard |
6、验证
可以通过命令查看服务的状态
1 | ceph mgr services |
当我们将cepenode1进行故障切换,再去验证则会发现集群对外是由cephnode2对外提供dashboard
1 | ceph mgr services |
事实上,你用
ss -tunlp | grep 8443命令,你会发现ceph mgr的两个节点上都监听了8443端口,只不过当访问备用节点时候,会重定向到当前主MGR节点的上服务
我们打开对应的IP地址网页,登录完成后的界面如下
8 添加OSD节点
当MGR节点添加完毕后,可以开始实施OSD节点的操作
OSD节点对硬件有一定的约束条件
8.1 必要条件
为Ceph添加OSD节点时,硬盘必须满足以下基本条件:
- 设备必须没有分区
- 不得安装设备
- 设备不得包含文件系统
- 设备不得包含 Ceph BlueStore OSD
- 设备必须大于 5 GB
清理残留数据:如果你发现目标硬盘上有未清理的分区或残留的Ceph数据,可以使用 ceph-volume lvm zap 命令来清除这些信息。
请注意,此操作会销毁磁盘上的所有数据,请务必提前确认操作对象是否正确
8.2 部署步骤
OSD服务部署相较MON服务会简化不少
1、在准备添加OSD前,你可以使用 lsblk 命令来查看服务器上所有磁盘设备的信
1 | lsblk |
不得有任何分区,容量要大于5GB
1 | fdisk -l |
2、使用ceph-volume 工具创建 OSD ID并将新的 OSD 添加到主机的 CRUSH 映射中
1 | ceph-volume lvm create --data /dev/sdb |
典型的返回结果如下:
1 | Running command: /usr/bin/ceph-authtool --gen-print-key |
我这里将典型返回结果进行了完整展示,目的是让读者看到ceph-volume工具的本质是按照自定义流程
上述自动化的运行command,大概的流程如下:
- 创建LVM:创建了Physical volume,然后Volume group,最后Logical volume “osd-block-d060ab27-d549-45ee-b35e-65ebe75312ed” 被创建成功
我们可以通过lvdisplay进行验证,注意这是个块设备,LV Status 为 available
1 | lvdisplay |
- 通过
ceph-authtool创建密钥,密钥位于/var/lib/ceph/osd/ceph-0/keyring,这点很重要 - 初始化OSD的数据目录
- 建立一个服务
ceph-volume@lvm-0-d060ab27-d549-45ee-b35e-65ebe75312ed.service,它的主要职责是在系统启动阶段,与 systemd 配合,激活在关机时被停用的 OSD,但是必须确保了 OSD 服务依赖的存储设备(如 LVM 逻辑卷)已经准备就绪,然后再启动 OSD 服务本身 - 启动Osd服务本身,注意这里采用
--runtime参数临时性的启用了ceph-osd@0.service服务
3、创建完成后,OSD服务即创建完毕
4、首先在cephnode1节点上验证osd服务状态,最便捷方式仍然使用ceph -s命令查看
1 | ceph -s |
使用ceph osd stat查看【后续我们推荐采用更加全面的ceph osd tree命令查看状态】
1 | ceph osd stat |
5【重要步骤】添加其他OSD节点
在/etc/ceph/ceph.conf配置文件中,虽然没有写,但是约定osd_pool_default_size = 3
即一份数据采用三副本的冗余方式,因此整个节点需要至少3个osd节点
因此需要继续在cephnode2和cephnode3上部署osd服务
【重要步骤】注意首先需要将初始化的mon节点上的/var/lib/ceph/bootstrap-osd/ceph.keyring拷贝至其他节点
1 | scp /var/lib/ceph/bootstrap-osd/ceph.keyring root@cephnode2:/var/lib/ceph/bootstrap-osd/ |
继续执行
1 | ceph-volume lvm create --data /dev/sdb |
注意这里的/dev/sdb根据实际情况进行调整
6、验证
1 | ceph -s |
注意观察重要的状态信息osd: 3 osds: 3 up (since 0.16818s), 3 in (since 7s)
要确保至少3个osd同时具备up和in状态
习惯于使用ceph osd tree命令查看树形状态,可以看出每个osd的编号等细节
7、验证【查看OSD tree】
1 | ceph osd tree |
这里的关系如下
1 | -1 (root default) |
在这个结构里:
root default是 CRUSH 层次结构的根桶 。所有其他的桶和 OSD 通常都组织在它的下面,是数据分布规则的起点。host cephnode1等是主机桶,代表一个物理服务器(或虚拟机),其下是该主机上运行的所有 OSD
8、【可选】通过dashboard验证
9、【教程待完善部分】当节点重启后,OSD进程无法正常启动
临时解决办法如下:
1 | ceph-volume lvm list |
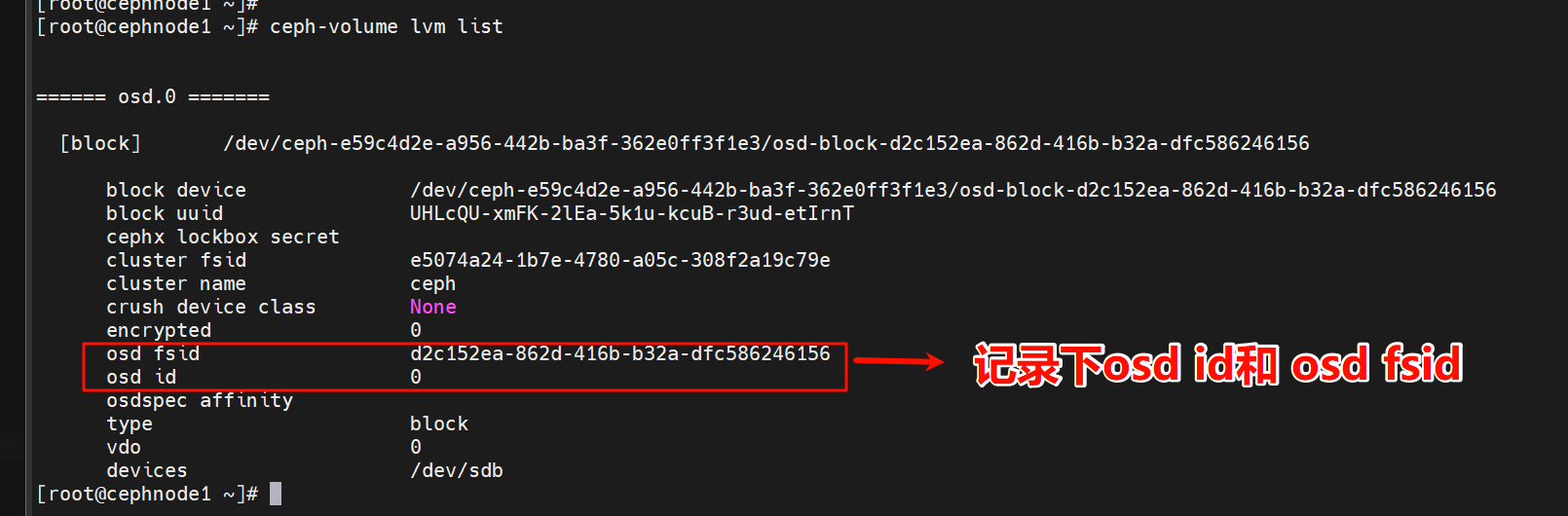
记录下osd id和osd fsid
然后继续将上述值代入以下命令ceph-volume lvm activate [osd id] [osd fsid]
1 | ceph-volume lvm activate 0 d2c152ea-862d-416b-b32a-dfc586246156 |
实际上ceph-volume这个命令本质就是一个python脚本
1 | file /usr/sbin/ceph-volume |
8 安装RADOSGW
RADOSGW,全称是 RADOS Gateway,它是Ceph分布式存储系统的一个对象存储服务网关
RADOSGW的主要作用就是让Ceph集群“变身”为一个与主流云平台兼容的对象存储服务
8.1 部署步骤
1、安装RadosGW
1 | yum install ceph-radosgw -y |
2、创建RadosGW的数据目录
1 | mkdir -p /var/lib/ceph/radosgw/ceph-cephnode1 |
3、创建一个具备完全读写和执行权限的”钥匙”,使其能够与Ceph的监控器(Mon)和存储守护进程(OSD)进行交互
1 | ceph auth get-or-create client.cephnode1 mon 'allow rwx' osd 'allow rwx' > /var/lib/ceph/radosgw/ceph-cephnode1/keyring |
4、启动服务
1 | systemctl enable ceph-radosgw@cephnode1.service |
5、验证
1 | systemctl status ceph-radosgw@cephnode1.service |
我们通过端口号进行验证,RadosGW服务默认端口是7480
1 | ss -tunlp | grep radosgw |
我们也可以通过dashboard进行验证
注意:在未创建RADOSGW服务前,此项是无法显示的
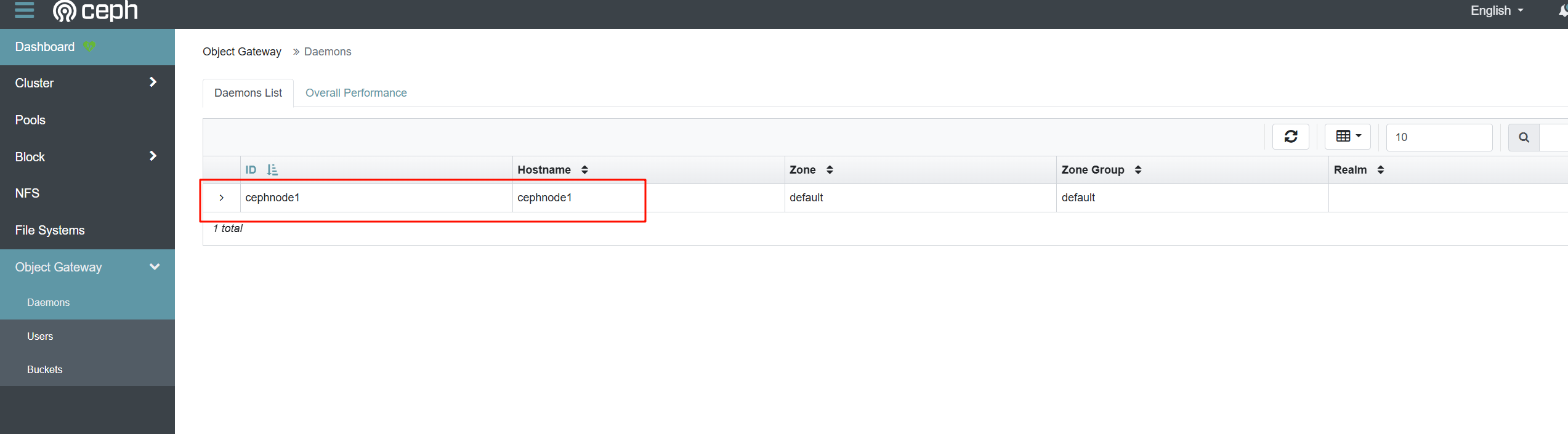
8.2 创建用户
当创建完RadosGW服务后,我们开始创建用户和bucket了
6、创建用户
radosgw-admin 命令行工具是创建和管理用户及存储桶(Bucket)的推荐且核心的方法之一
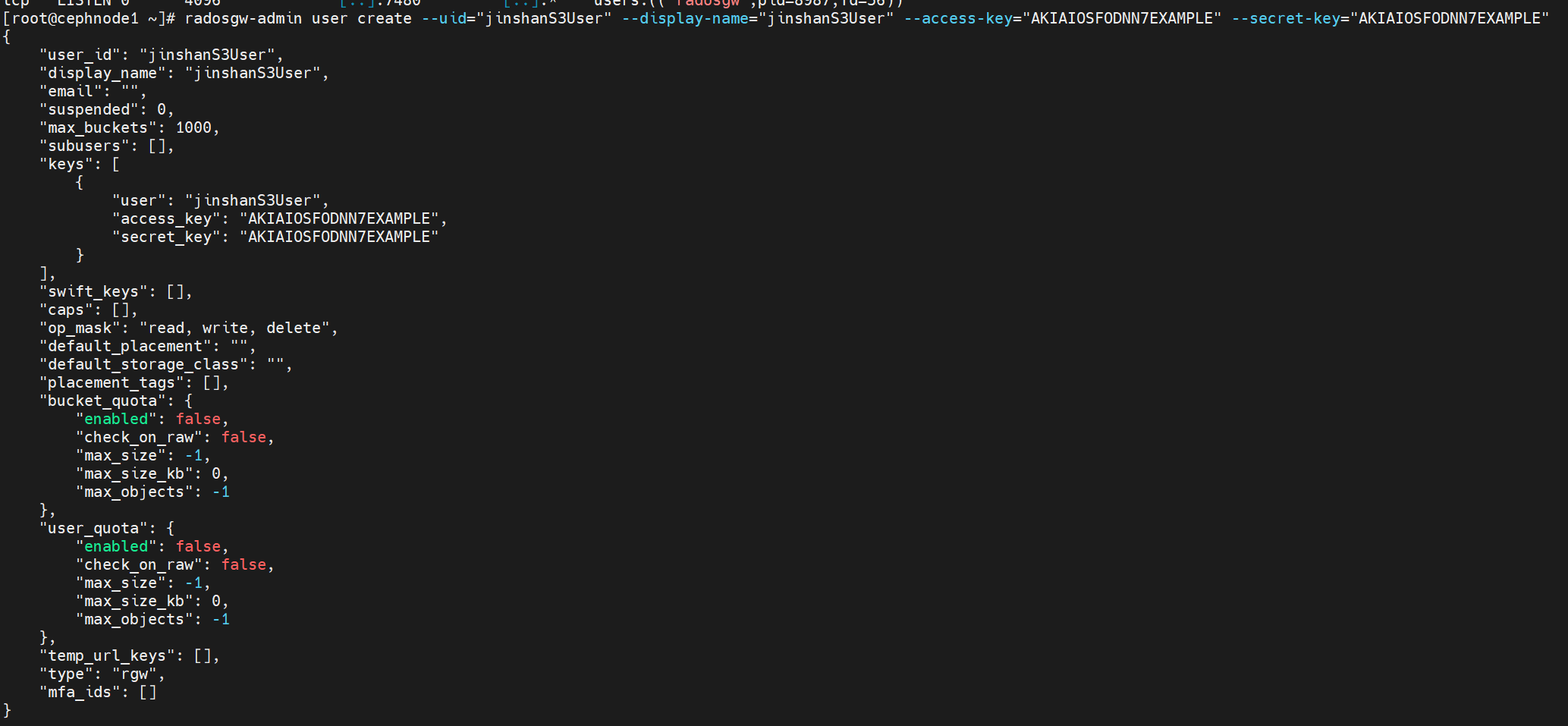
1 | radosgw-admin user create --uid="jinshanS3User" --display-name="jinshanS3User" --access-key="AKIAIOSFODNN7EXAMPLE" --secret-key="AKIAIOSFODNN7EXAMPLE" |
这个命令的核心功能是创建一个新的S3接口用户。具体参数含义如下:
--uid="jinshanS3User":【必选参数】设置用户ID为“jinshanS3User”,这是用户在系统中的唯一标识--display-name="jinshanS3User":【必选参数】设置用户的显示名称为“jinshanS3User”--access-key="AKIAIOSFODNN7EXAMPLE":手动指定用户的访问密钥ID为“AKIAIOSFODNN7EXAMPLE”。这类似于AWS S3的Access Key ID,用于身份验证--secret-key="AKIAIOSFODNN7EXAMPLE":手动指定用户的秘密访问密钥为“AKIAIOSFODNN7EXAMPLE”。这类似于AWS S3的Secret Access Key,与Access Key配套使用
如果命令成功执行,通常会返回一个JSON格式的用户信息,其中就包含您指定的访问密钥和秘密密钥
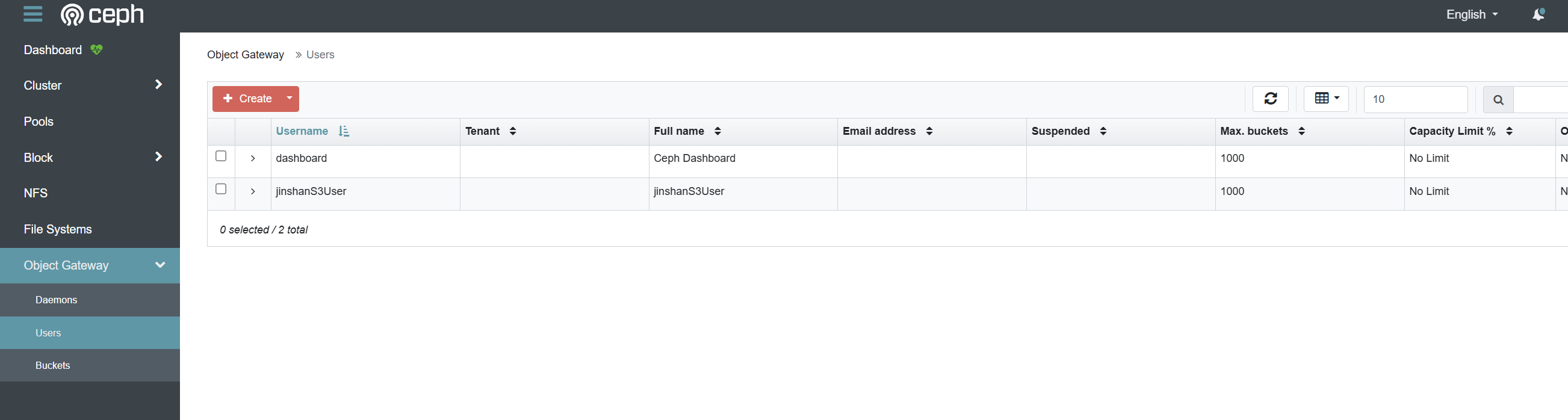
7、验证
你可以使用 radosgw-admin user info --uid=<uid> 命令来查询用户的详细信息,这其中就包含访问密钥
此时我们可以在dashboard中查看用户
8.3 创建bucket及客户端实战
这里我们选择使用MinIO客户端进行实战部署测试
https://www.minio.org.cn/download.shtml#/linux
下载完成后直接使用二进制文件执行
1 | wget https://dl.minio.org.cn/client/mc/release/linux-amd64/mc |
8、设置测试服务器的别名
为MinIO客户端创建别名,主要是为了简化操作和集中管理配置,让日常的文件和存储桶管理变得更高效
用法是mc alias set myminio/ http://MINIO-SERVER MYUSER MYPASSWORD
具体如下:
1 | ./mc alias set cephradosrw http://192.168.10.131:7480 AKIAIOSFODNN7EXAMPLE AKIAIOSFODNN7EXAMPLE --api s3v4 |
如果报错信息如下
1 | mc: <ERROR> Unable to initialize new alias from the provided credentials. Get "https://192.168.10.131:7480": http: server gave HTTP response to HTTPS client. |
注意在./mc alias set参数添加--api s3v4的参数,强制 MinIO 客户端使用了与您的 Ceph RADOS 网关服务端相匹配的、更新且更安全的签名算法
9、验证别名服务配置信息。验证的主要目的用于检验AccessKey和SecretKey是否错误
1 | ./mc alias ls cephradosrw |
10、创建一个测试用bucket
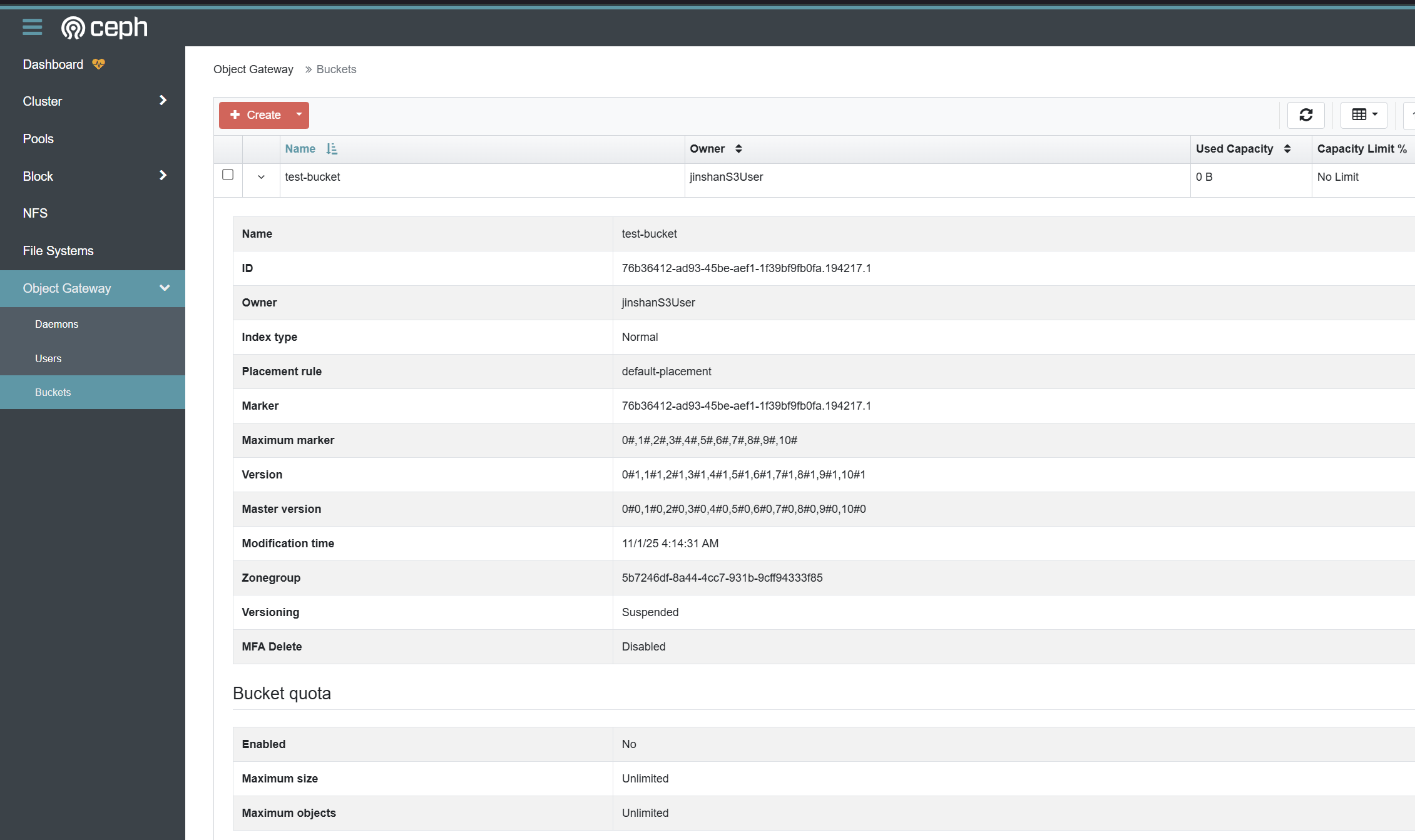
1 | ./mc mb cephradosrw test-bucket |
11、验证刚创建好的bucket
可以在dashboard直接查看
12、上传文件
1 | ./mc cp anaconda-ks.cfg cephradosrw/test-bucket |
13、验证
列出bucket下文件
1 | ./mc ls cephradosrw/test-bucket |
显示文件详细信息
1 | ./mc stat cephradosrw/test-bucket/anaconda-ks.cfg --json |
查找搜索文件
1 | ./mc find cephradosrw/test-bucket --name "*.cfg" |
下载文件
1 | ./mc get cephradosrw/test-bucket/anaconda-ks.cfg |
9 调试和排错
9.1 调试
9.1.1 集群整体状态
使用ceph health detail查看集群的整体健康状态,包含WRN的一个典型的输出如下:
1 | HEALTH_WARN mons are allowing insecure global_id reclaim; clock skew detected on mon.cephnode2; 3 monitors have not enabled msgr2; OSD count 0 < osd_pool_default_size 3 |
9.1.2 MON节点
排查MON问题时,可以先用 ceph -s 看整体状态
需要详细信息时可考虑 ceph mon dump
典型的结果如下:
1 | ceph mon dump |
9.1.3 OSD节点
需要掌握状态查看细节
除了使用ceph osd stat外,常用的检查命令包括
| 检查方向 | 常用命令示例 | 简要说明 |
|---|---|---|
| OSD状态概览 | ceph osd stat |
查看OSD map版本、总数、up和in的OSD数量。 |
| OSD树状结构 | ceph osd tree |
以树形结构显示OSD在CRUSH地图中的分布、状态及权重。 |
| OSD使用情况 | ceph osd df |
详细列出每个OSD的磁盘使用空间和比例。 |
| 归置组状态 | ceph pg stat |
查看PG的整体状态。 |
| 存储池统计 | ceph osd pool stats |
查看各个存储池的实时IOPS和吞吐量等性能数据。 |
| 集群空间用量 | ceph df 或 ceph df detail |
查看集群全局及每个存储池的磁盘空间使用情况。 |
- 理解
up和in的状态:这是OSD的核心状态。up:OSD守护进程正在运行in:OSD被纳入集群,数据可以被分布到该OSD- 一个健康的OSD通常应该同时是
up且in。如果OSD是down但却仍然in,会导致集群健康报警,因为集群无法向它写入数据。
- 关注PG状态:归置组的状态直接反映了数据的状态。你需要特别留意例如
degraded(降级,数据副本不足)、recovering(正在恢复)、stuck unclean(卡在非干净状态)等非正常状态,这些通常意味着数据可能存在风险或正在迁移
如果发现某个OSD状态为down,可以尝试登录到该OSD所在节点,使用 systemctl start ceph-osd@<OSD_ID> 命令启动它
9.2 排错
1、时间不同步,使用ceph -s会报错
1 | clock skew detected on mon.cephnode2, mon.cephnode3 |
进一步使用ceph health detail
1 | HEALTH_WARN mons are allowing insecure global_id reclaim; clock skew detected on mon.cephnode2, mon.cephnode3; 3 monitors have not enabled msgr2 |
Ceph 对节点间的时间同步有极其严格的要求,默认允许的最大时钟偏差(clock skew)只有 0.05 秒(50毫秒)
在上述警告信息中:
cephnode2的时钟偏差为 0.395秒 > 0.05秒cephnode3的时钟偏差为 0.472秒 > 0.05秒
这意味着这三个 Monitor 节点的系统时间相差了近半秒钟,严重超出了 Ceph 的容限范围
解决办法:只需要使用诸如chronyd服务使得所有节点时钟同步即可
2、OSD部署时候未部署秘钥文件
当创建OSD节点服务时候,无法创建服务,提示未发现秘钥文件
1 | stderr: 2025-10-31T02:47:24.369+0800 7f06527fb640 -1 auth: unable to find a keyring on /var/lib/ceph/bootstrap-osd/ceph.keyring: (2) No such file or directory |
解决办法:将MON初始化节点的bootstrap-osd/ceph.keyring秘钥文件拷贝到目标节点上
1 | scp /var/lib/ceph/bootstrap-osd/ceph.keyring root@cephnode3:/var/lib/ceph/bootstrap-osd/ |
3、Ceph集群的Monitor节点配置为允许不安全的全局ID回收
简单来说,这个警告涉及Ceph的认证安全。Ceph集群的Monitor节点配置为允许不安全的全局ID回收,这可能导致潜在的安全风险
Ceph集群出现 AUTH_INSECURE_GLOBAL_ID_RECLAIM_ALLOWED 健康警告
使用ceph health detail列出所有尚未更新的客户端
1 | [WRN] AUTH_INSECURE_GLOBAL_ID_RECLAIM_ALLOWED: mons are allowing insecure global_id reclaim |
解决办法:确认所有客户端都已更新后,执行以下命令禁用不安全的回收选项:
1 | ceph config set mon auth_allow_insecure_global_id_reclaim false |
再次运行 ceph health 或 ceph health detail,确认 AUTH_INSECURE_GLOBAL_ID_RECLAIM_ALLOWED 警告已经消失。同时,确保没有客户端因配置变更而出现连接问题
处理 AUTH_INSECURE_GLOBAL_ID_RECLAIM_ALLOWED 警告,关键在于先升级所有客户端组件,然后才在Monitor上禁用不安全的全局ID回收选项。这样做既能消除安全警告,又能确保集群的稳定运行
修复命令
ceph config set mon auth_allow_insecure_global_id_reclaim false,其作用就是关闭这个不安全的后门,强制所有客户端都必须遵守最严格的安全流程
4、Ceph Monitor 未启用新的 msgr2 消息传递协议
运行ceph -s时,出现1 monitors have not enabled msgr2错误
原因:Ceph Monitor 未启用新的 msgr2 消息传递协议
要解决这个问题,你只需要在 Ceph 集群的任意管理节点 上执行一条命令:
1 | ceph mon enable-msgr2 |
启用msgr2协议后务必打开3300/tcp的防火墙端口
msgr2协议(Messenger v2)是Ceph新一代的线上协议,它主要带来了两个重要特性:
crc模式:提供完整性校验,能防止”比特反转”攻击,但不加密网络流量。secure模式:在crc模式的基础上,对所有认证后的网络流量进行完全加密,并提供加密完整性检查。
关于端口:
- msgr2协议默认使用3300端口
- 传统的msgr1协议则使用6789端口
- 默认情况下,Ceph守护进程会同时绑定到v1和v2协议的端口(
ms_bind_msgr1和ms_bind_msgr2都默认为true),这确保了新旧客户端的兼容性
5、Mon节点丢失
执行ceph -s命令后,出现典型的错误信息:
quorum cephnode1,cephnode3: 当前形成法定人数的节点是 cephnode1 和 cephnode3
out of quorum: cephnode2: cephnode2 :不在法定人数中,失去了与其他 MON 节点的通信
6、osd数据目录丢失
解决办法:使用 ceph-volume 扫描并激活
1 | # 扫描所有 OSD |